Research - Legacy - HRI-CMM
Research
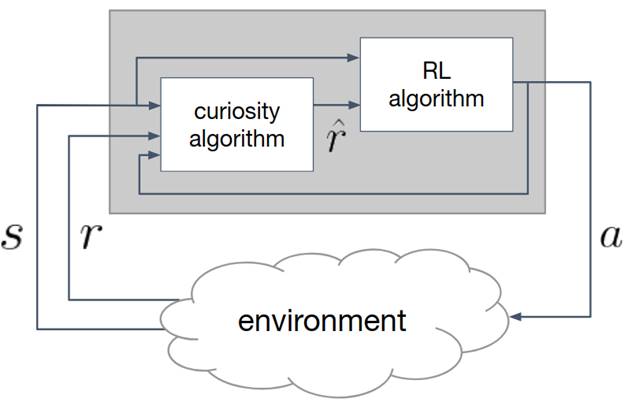
Since May 2018, Honda Research Institute has collaborated with research teams from Massachusetts Institute of Technology (MIT), University of Pennsylvania, and University of Washington to investigate the concept of curiosity in humans and machines.
Our ultimate goal is to create new types of machines that can acquire an interest in learning and knowledge, the ability to learn and discover, and the ability to interact with the world and others. We want to develop Curious Minded Machines that use curiosity to serve the common good by understanding people’s needs, empowering human productivity, and ultimately addressing complex societal issues.
For more information about each team’s research, click on the university logos >>
When interacting with humans, the team believes that curiosity can drive a robot to learn what might be most useful in the long term or relevant for their users, and a robot perceived as curious or inquisitive will be more acceptable to its users given its limitations, such as the inability to perform some tasks or mistakes it makes in available tasks.
Over the past year, the University of Washington team has made significant progress across three main research axes: 1) understanding and modeling of human perceptions towards curious robot behaviors; 2) autonomous generation of curious robot behaviors; 3) robot perception for curiosity-driven learning.
Read More
1. Understanding human perceptions towards curious robot behaviors
How do humans perceive and react to curious robots? In what situations and contexts do humans attribute curiosity to robot behaviors? In what cases is robot curiosity desirable?
The team is analyzing parent-child interviews and survey data to understand how curiosity is viewed and conceptualized in a robot. For instance, parental difference in technology experiences may impact how parents teach children to conceptualize robots as an ambiguous ontological category straddling various levels of aliveness. This perception of what a robot inherently is may alter the affordance and autonomy levels participants expect a robot to have as well as differences in preference for the way it behaves toward/around them.

Understanding Human Perception of and Attitudes towards Robot Curiosity
To explore people's perceptions of robot curiosity, the University of Washington team is manipulating a robot's behavior in different ways to understand what might be perceived as curiosity in a robot and whether that is a preferred/likable attribute for a robot. Following up on the project last year (Walker et al., 2020), the team is conducting a follow-up experiment that examines whether people would view a robot differently depending on how curious it acted and whether or not it was seen as busy performing a task for a person.
Publication:
N. Walker, K. Weatherwax, J. Alchin, L. Takayama, and M. Cakmak, “Human Perceptions of a Curious Robot that Performs Off-Task Actions,” in ACM/IEEE International Conference on Human-Robot Interaction (HRI), 2020, pp. 529–538.
2. Autonomous generation of curious robot behaviors
Leveraging our understanding of the human mechanisms underlying the attribution of curiosity to robot behaviors, we focus on the generation of curious robot behaviors and study its implications for human observers. The latest research on Bayesian Reinforcement Learning from the team of Prof. Srinivasa involving the Bayesian Residual Policy Optimization explores a scalable, efficient framework for Bayesian Reinforcement Learning that constitutes an improvement to the Bayesian Policy Optimization framework. Further, the teams led by Profs. Cakmak, Takayama and Srinivasa are developing frameworks for autonomous generation of curiously-looking motion and of help queries for navigation tasks.
Bayes-Adaptive Markov Decision Processes for Curiosity-Driven Learning
Can curiosity naturally arise during learning? Can curiosity-driven robots learn to solve complex tasks data-efficiently? The University of Washington team propose a belief-space representation of the world, in which robots maintain a belief (distribution over hypotheses) over the unknowns, as a mathematically elegant way to capture curiosity. We show that Bayesian reinforcement learning (BRL) in this belief space results in naturally curious behaviors that benefit long term task performance, even for multi-task settings where future tasks may be different from the current one.
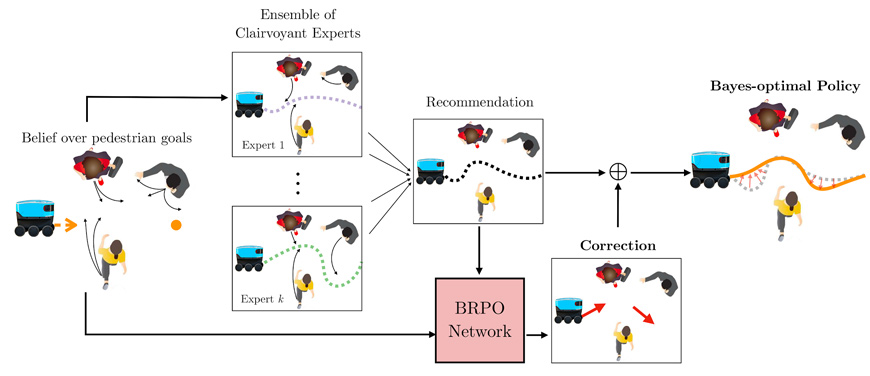
Publications:
G. Lee, B. Hou, S. Choudhury, S. S. Srinivasa, “Bayesian Residual Policy Optimization: Scalable Bayesian Reinforcement Learning with Clairvoyant Experts,” In Workshop on Interactive Robot Learning, IEEE International Conference on Robotics and Automation. 2020.
Gilwoo Lee, “Scalable Bayesian Reinforcement Learning,” PhD Thesis. University of Washington. 2020.
Generating Robot Behaviors that are Perceived as Curious
The team aims to create an agent that can autonomously generate behavior perceived as curious by a human observer. Standard exploration strategies for learning agents tend to optimize for only task performance objectives, resulting in behavior typically perceived as goal-directed or efficient. The team models the human process of behavioral attribution to robot trajectories as probabilistic classification. The study is conducted on a simplified 2D home vacuum cleaner environment to examine human perceptions of robot trajectories in household domains with the goal of learning models of curiosity attribution to robot motion.
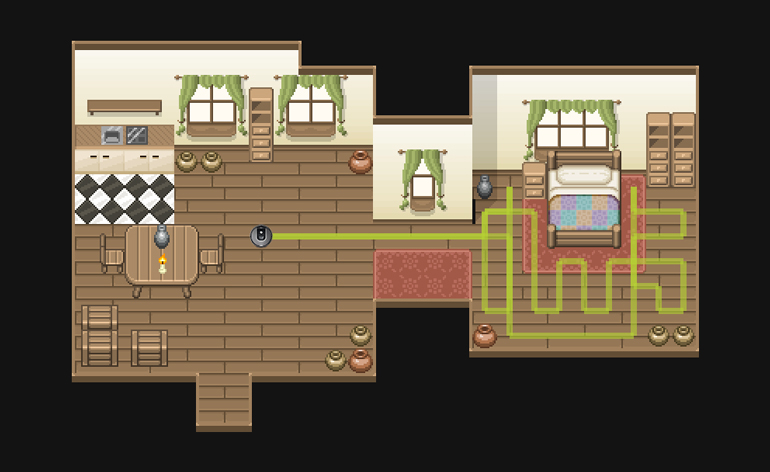
Publication:
N. Walker, C. Mavrogiannis, S. Srinivasa, M. Cakmak, Anonymous Submission, 2021.
Generating Curious Robot Help Queries
Robots that curiously learn about the world will need to ask humans for help. For example, consider a new office aide robot that is learning about the building. It may need to ask humans for the colloquial name of particular locations, or where to find particular people or objects. It may also want to curiously ask for help to increase its knowledge base, even if that knowledge is not immediately relevant for the task immediately at hand. The aim of this project is to develop a model and planning framework that enables the robot to effectively ask humans for help. Our model disaggregates between the individual and contextual factors involved in human help-giving behavior, and our associated POMDP planning framework enables the robot to curiously learn how inherently helpful humans are over repeated interactions with them.
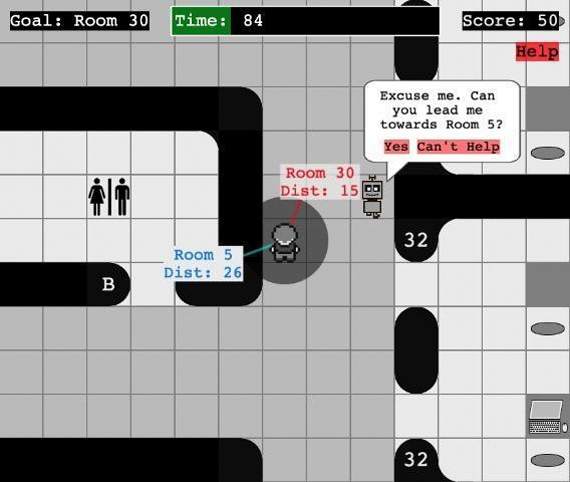
Publication:
A. Nanavati, C. Mavrogiannis, K. Weatherwax, L. Takayama, M. Cakmak, S. Srinivasa, Anonymous Submission, 2021.
3. Robot perception for curiosity-driven learning
Curiously exploring a human environment often entails reasoning about unseen objects and their physical properties. The team has been developing important components for robot perception that enable curiosity-driven learning of novel tasks in human environments. These include models for segmentation of previously unseen objects; models for pose and state estimation; and models for world dynamics applicable to manipulation tasks such as dirt cleaning.
Researchers' long-term goal is to build intelligent robots that can curiously explore, learn, and adapt to new environments. A fundamental building block toward realizing a curiosity-driven robot is a perception system capable of identifying and isolating potentially unseen objects in an arbitrary unstructured environment.
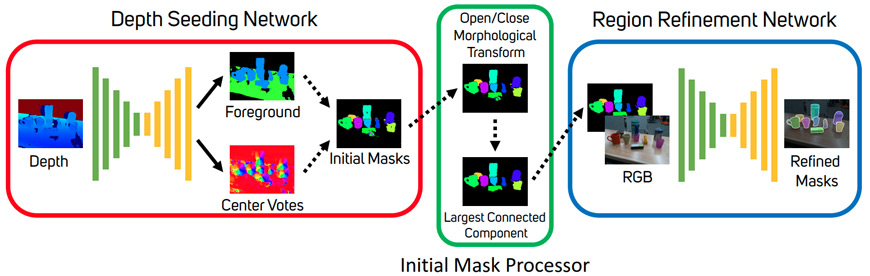
Publications:
Christopher Xie, Yu Xiang, Arsalan Mousavian, and Dieter Fox, “The Best of Both Modes: Separately Leveraging RGB and Depth for Unseen Object Instance Segmentation,” Conference on Robot Learning – CoRL, 2019.
Christopher Xie, Yu Xiang, Arsalan Mousavian, and Dieter Fox, “Unseen Object Instance Segmentation for Robotic Environments.” arXiv, 2020. [https://arxiv.org/abs/2007.08073].
To seamlessly learn from the interactions, it is essential to equip an intelligent robot with efficient ways to localize and track object entities in motion. In the context of manipulation tasks, estimating and tracking 6D poses of objects from sensor data is an important problem. To address this problem, in this project, we are developing a novel deep neural network for 6D pose matching named DeepIM, which matches hypothesized poses (rendered images) of an object against the observed input image to produce accurate results.
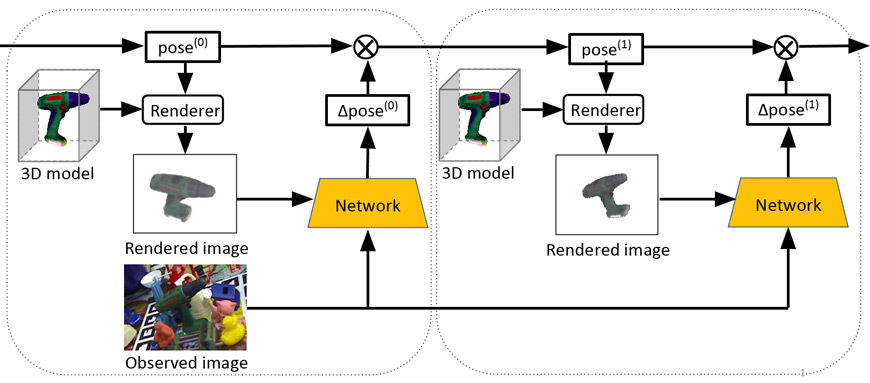
Curiosity-Driven Learning of World Dynamics
The team led by Prof. Cakmak and Prof. Fox is exploring the key learning problem of "world dynamics", i.e. how the dirt changes when an action with a cleaning tool is applied to it. The team is currently investigating how different exploration strategies result in different learning curves and eventual models of the robot's transition function that represent those dynamics. We would like the robot to effectively clean various types of dirt on different surfaces. The robot can gain this ability by being “curious” about how the dirt moves even though modeling this motion will initially make the task of sweeping it away inefficient.

The University of Pennsylvania defines curiosity as a strategic mode of exploration, adopted by an agent in order to maximize future rewards on tasks yet to be specified, but useless with regards to the current task(s).
Over the past year, the University of Pennsylvania team focused on what uncertainty measures could be used for intrinsic reward and continued its work on social curiosity and action representations.
Read More
Adversarial Curiosity
The University of Pennsylvania team continued its work on adversarial curiosity where they use a discriminator score as novelty. The new experiments demonstrate progressively increasing advantages of the adversarial curiosity approach over leading model-based exploration strategies, when computational resources are restricted. The team further demonstrated the ability of the adversarial curiosity method to scale to a robotic manipulation prediction-planning pipeline under improved sample efficiency and prediction performance for a domain transfer problem.
Publications:
B. Bucher*, K. Schmeckpeper*, N. Matni, K. Daniilidis, “An Adversarial Objective for Scalable Exploration,” arXiv Preprint, 2020.
B. Bucher, A. Arapin, R. Sekar, F. Duan, M. Badger , K. Daniilidis, O. Rybkin. “Perception-Driven Curiosity with Bayesian Surprise,” In RSS Workshop on Combining Learning and Reasoning Towards Human-Level Robot Intelligence, 2019.
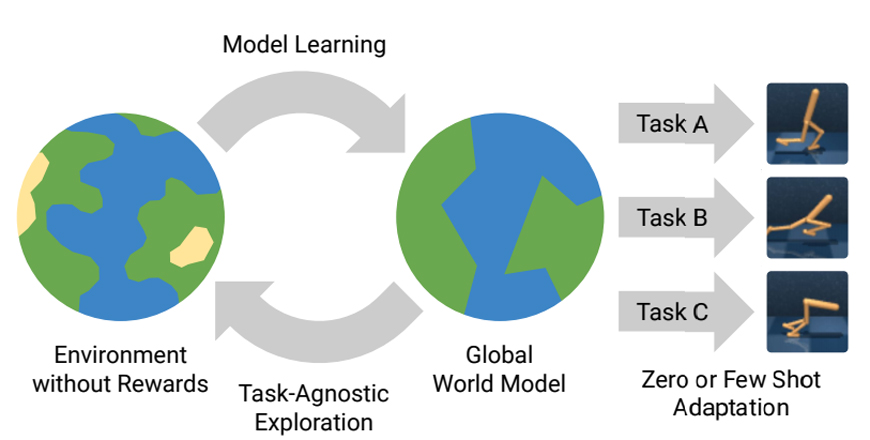
Planning to explore via Latent Disagreement
Exploring and learning the world model without rewards, the team used the disagreement of latent representations as novelty. In this approach, latent disagreement (LD), efficiently adapts to a range of control tasks with high-dimensional image inputs. While current methods often learn reactive exploration behaviors to maximize retrospective novelty, we learn a world model trained from images to plan for expected surprise.
Publication:
R. Sekar, O. Rybkin, K. Daniilidis, P. Abbeel, D. Hafner, and D. Pathak, “Planning to explore via self-supervised world models,” In Int. Conf. Machine Learning (ICML), 2020.
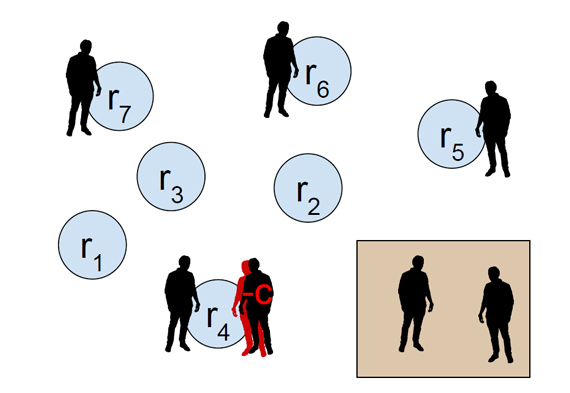
Social Curiosity
A competitive resource allocation problem is visualized here with a collection of agents, a collection of locations associated with different reward values, and a “home" location for the agents. The team hypothesized that adding curiosity, an intrinsic motivation to seek knowledge observed in cognitive systems, to agent strategies will change learning dynamics which will benefit some multi-agent systems. Through the experiments, the team demonstrates that agents using a count-based curiosity reward achieve faster convergence to a more equal distribution of rewards across agents than agents following a greedy strategy in a competitive resource allocation task.
Publication:
B. Bucher, S. Singh, C. de Mutalier, K. Daniilidis, and V. Balasubramanian, “Curiosity increases equality in competitive resource allocation,” In Bridging AI and Cognitive Science Workshop (ICLR 2020), 2020.
Curious exploration in complex environments
Curiosity is widely recognized as a fundamental mode of cognition, driving people and animals toward novel experiences that yield new insights about the world and its underlying processes. Curiosity is therefore linked to information-seeking in novel environments and is an important part of behavior that we perceive as “intelligent." While simple greedy actors may be optimal in simple and highly determinate environments, it is expected that curiosity is beneficial in more complex, evolving environments. The question of curiosity is approached by comparing reinforcement learning agents using different phenomenological models of curiosity in environments of controlled complexity.
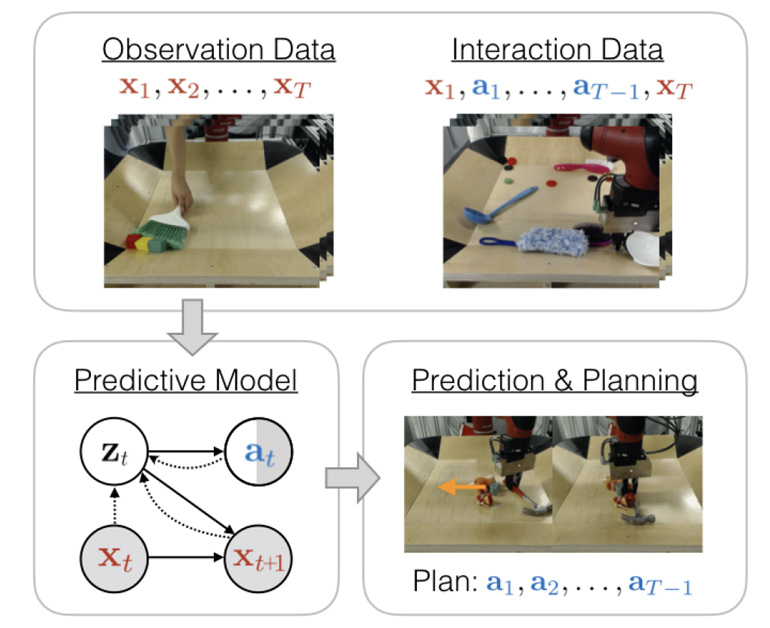
Prediction through Observation and Interaction
Humans have the ability to learn skills not just from their own interaction with the world but also by observing others. Consider an infant learning to use tools. In order to use a tool successfully, it needs to learn how the tool can interact with other objects, as well as how to move the tool to trigger this interaction. Such intuitive notions of physics can be learned by observing how adults use tools. In this project, the team considers this problem: can agents learn to solve tasks using both their own interaction and the passive observation of other agents?
Publication:
K. Schmeckpeper, A. Xie, O. Rybkin, S. Tian, K. Daniilidis, S. Levine, and C. Finn. Learning predictive models from observation and interaction. In European Conference on Computer Vision (ECCV), 2020.
Learning Object Placement by Inpainting for Compositional Data Augmentation
Studies in humans and animals suggest that the mental replay of past experiences is essential for enhancing visual procession as well as making action decisions. We ask the question: can developing a computational mental replay model help to improve AI visual perception tasks such as recognition and segmentation? More specifically, would the mental replay of object placement and scene affordance boost visual recognition systems?
Motivated by vast amount of driving scenes in public datasets, the team created a self-supervised mental replay task of learning object placements into street scenes, and proposed PlaceNet, which predicts the location and scale to insert the object into the background.

Publication:
L. Zhang, T. Wen, J. Min, J. Wang, D. Han, and J. Shi, “Learning Object Placement by Inpainting for Compositional Data Augmentation,” In Computer Vision - ECCV 2020. Springer International Publishing, 2020.
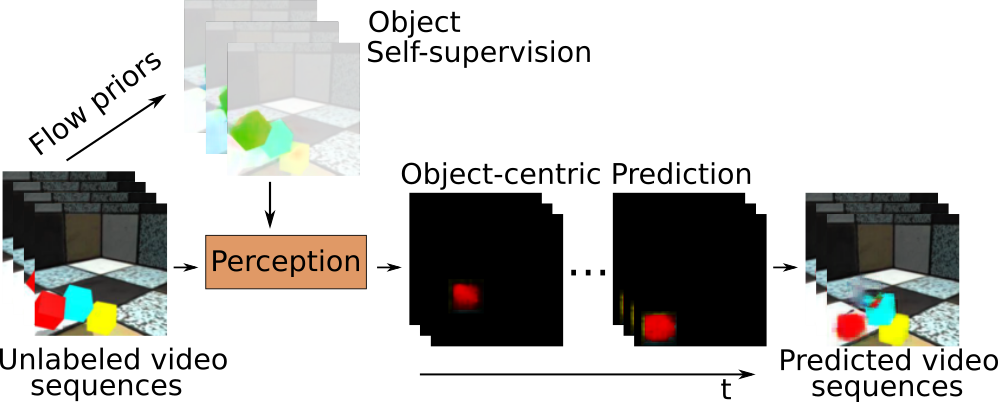
Object-centric Video Prediction without Annotation
In order to interact with the world, agents must be able to predict the results of the world's dynamics. A natural approach to learn about these dynamics is through video prediction, as cameras are ubiquitous and powerful sensors. Direct pixel-to-pixel video prediction is difficult, does not take advantage of known priors, and does not provide an easy interface to utilize the learned dynamics. Object-centric video prediction offers a solution to these problems by taking advantage of the simple prior that the world is made of objects and by providing a more natural interface for control. However, existing object-centric video prediction pipelines require dense object annotations in training video sequences. In this work, we present Object-centric Prediction without Annotation (OPA), an object-centric video prediction method that takes advantage of priors from powerful computer vision models. We validate our method on a dataset comprised of video sequences of stacked objects falling, and demonstrate how to adapt a perception model in an environment through end-to-end video prediction training.
Publication:
K. Schmeckpeper*, G. Georgakis*, K. Daniilidis, “Object-centric Video Prediction without Annotation”, In International Conference on Robotics and Automation (ICRA) 2021. *Equal contribution.
Learning to Map for Active Semantic Goal Navigation
We consider the problem of object goal navigation in unseen environments. In our view, solving this problem requires learning of contextual semantic priors, a challenging endeavour given the spatial and semantic variability of indoor environments. Current methods learn to implicitly encode these priors through goal-oriented navigation policy functions operating on spatial representations that are limited in the agent's observable areas. In this work, we propose a novel framework that actively learns to generate semantic maps outside the field of view of the agent and leverages the uncertainty over the semantic classes in the unobserved areas to decide on long term goals. We demonstrate that through this spatial prediction strategy, we are able to learn semantic priors in scenes that can be leveraged in unknown environments. Additionally, we show how different objectives can be defined by balancing exploration with exploitation during searching for semantic targets. Our method is validated in the visually realistic environments offered by the Matterport3D dataset and show state of the art results on the object goal navigation task.

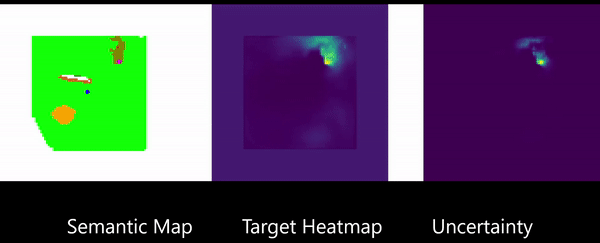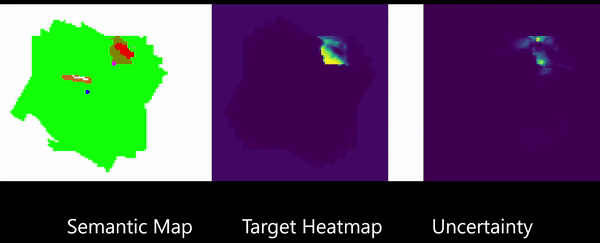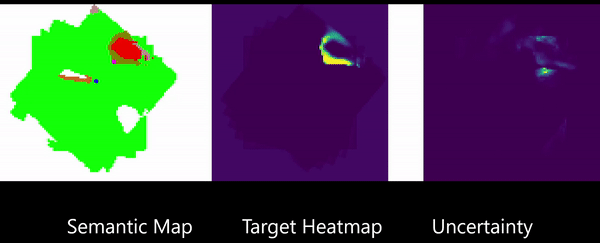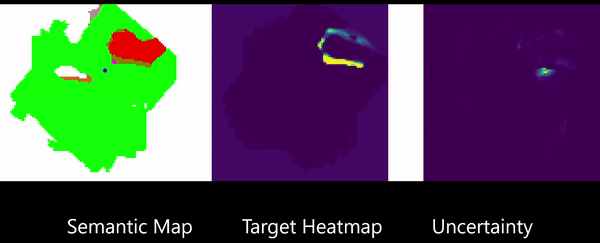
Publication:
G. Georgakis*, B. Bucher*, K. Schmeckpeper, S. Singh, K. Daniilidis, “Learning to Map for Active Semantic Goal Navigation.” (under submission). *Equal contribution.
The MIT team is researching curiosity as a mechanism for acquiring a predictive theory of the world as well as examining how algorithmic science can learn from the study of developmental psychology. They also are exploring several hypotheses about how children learn, what they learn and why, by embodying these hypotheses and testing them in their Curious Minded Machines.
In the first task, they are investigating how a period of “curious” but directed interaction with mechanisms can lead to the ability to actuate never-before-seen mechanism instances with very few (sometimes just one) trials. In the second task, they are investigating on exploration methods for lifted operator learning called Goal-Literal Babbling that avoids problems of previous planning techniques for curiosity and exploration. In the third task, they are investigating meta-learning. Taking inspiration from transductive learning, they have shown how to find a shared “meta-hypothesis” across tasks, allowing the model to be adapted to each particular input for a customized fit, eliminating generalization error on the auxiliary loss.
Curious Model Learning
The MIT team is focusing its research on learning models of objects in the environment. They hypothesize that a robot with a curious sub-goal proposal mechanism can learn models that are “better” by using experience from its sub-goals to update the model. In this case, “better” means the model is better suited to succeeding in future tasks.
They are currently investigating how to enable a robot to efficiently interact with novel objects with unusual dynamics, where the robot can learn the impact of the unusual dynamics from previous visuo-motor experience with related objects without human guidance.
Publication:
C. Moses, M. Noseworthy, L.P. Kaelbling, T. Lozano-Pérez, N. Roy, “Visual Prediction of Priors for Articulated Object Interaction,” IEEE International Conference on Robotics and Automation (ICRA), 2020.
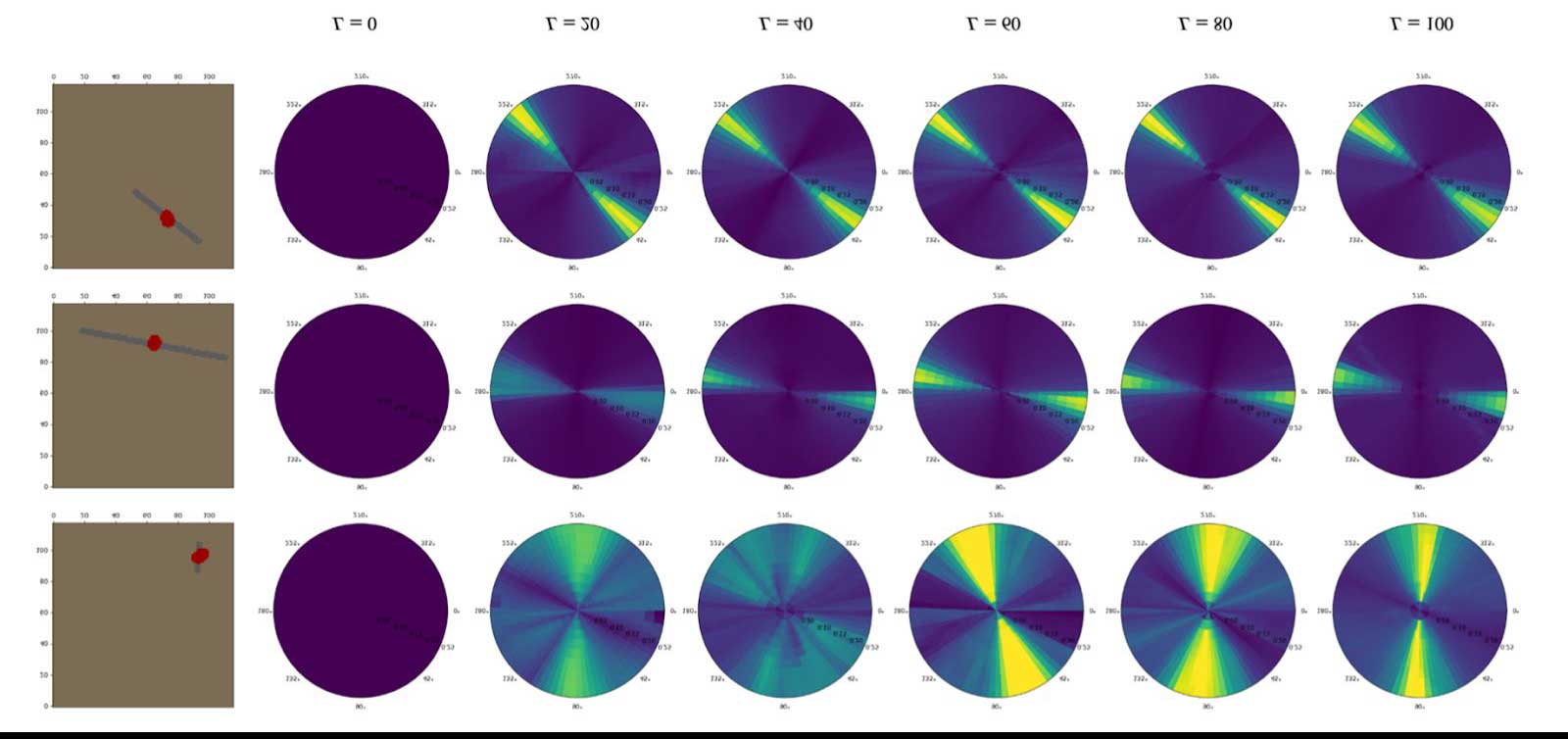
Compositional Skill Learning through Curiosity-Driven Compilation of Hierarchical Policies
Curiosity-driven exploration means to explore parts of the environment about which we do not know. The MIT team hypothesizes that a curious agent should, when faced with a set of training settings that do not have extrinsic goals/rewards, learn useful high-level policies that can be composed in various ways through planning, in order to succeed quickly at longer-horizon tasks..
In pursuit of an exploration strategy that can drive an agent toward interesting regions of the state space, the teams proposes a novel family of exploration methods for relational transition model learning called Goal-Literal Babbling (GLIB).
Publication:
R. Chitnis, T. Silver, J. Tenenbaum, L. Kaelbling and T. Lozano-Pérez. “GLIB: Efficient Exploration for Relational Model-Based Reinforcement Learning via Goal-Literal Babbling”. Proceedings of the National Conference on Artificial Intelligence (AAAI), 2021.
Meta-Learning Curiosity Algorithms
The MIT team aims to find a curiosity module that achieves high total long-term reward in many different environments. They hypothesize that curiosity is an evolutionary-found system that encourages meaningful exploration in order to get high long-term reward, and propose to frame this evolutionary search in algorithm space.
The team is investigating in formulating the problem of generating curious behavior as one of meta-learning. The team aims at generalization between completely different environments, even between environments that do not share the same I/O spec. It is done by transferring algorithms rather than network policies or features.
Publications:
F. Alet, M. Schneider, T. Lozano-Perez, L. P. Kaelbling. Meta-learning curiosity algorithms. In International Conference on Learning Representations, 2020.
F. Alet*, J. Lopez-Contreras*, J. Koppel, M. Nye, A. Solar-Lezama, T. Lozano-Pérez, L. Kaelbling and J. Tenenbaum. “Measuring few-shot extrapolation”. NeurIPS Computer Assisted Programming workshop, 2020.
F. Alet, K. Kawaguchi, M. Bauza, N. Kuru, T. Lozano-Pérez and L. Kaelbling. “Tailoring, encoding inductive biases by optimizing unsupervised objectives at prediction-time”. NeurIPS Inductive Biases workshop, 2020.
Learning Universal Curiosity
The MIT team will test the hypothesis that curiosity is driven by an intrinsic reward function that can be learned from heuristic reward functions that are externally encoded. Therefore, the intrinsic reward function has internal structure encoded as sub-goals.
An intrinsic reward function is typically hand-designed and used to guide exploration within a single reinforcement learning task. The team instead proposes to learn an intrinsic reward that works across many tasks. The team is continuing to study human creative tool use, focusing on understanding both what is learned during performance, and what people think is important to learn.
Publication:
Allen, K. R., Smith, K. A., & Tenenbaum, J. B. (2020). Rapid trial-and-error learning with simulation supports flexible tool use and physical reasoning. Proceedings of the National Academy of Sciences, 117(47), 29302–29310.