Research - HRI-CMM
Research
From May 2018 to July 2021, Honda Research Institute collaborated with research teams from Massachusetts Institute of Technology (MIT), University of Pennsylvania, and University of Washington to investigate the concept of curiosity in humans and machines. Our goal was to develop Curious Minded Machines that use curiosity to serve the common good by understanding people’s needs, empowering human productivity, and ultimately addressing complex societal issues.
Together with 11 principal investigators and over 30 students and post-doctoral researchers, we explored and acquired expertise in the area of artificial curiosity. Our results include mathematical models of curiosity as well as findings on the effects of robotics curiosity to humans in human-robot interaction, improvement of cognitive ability through curiosity, prediction and modeling of an environment based on curious exploration and experience, and discovery of new algorithms through curiosity. Two capstone demonstrations were designed to clarify the value of curiosity in an autonomous system.
In addition to hosting annual workshops with the research teams, Honda Research Institute held a workshop on curious robots at the 2021 International Conference on Robotics and Automation (ICRA2021). We presented the value of curiosity in an autonomous system to an audience of more than 180 researchers. Honda Research Institute continues to investigate the Curious Minded Machine as one of the directions toward the next level of AI to serve people’s needs.
Over the 3-year period of the CMM project, The UW team made significant contributions across a number of threads relating to the value of curiosity for robotics and human-robot interaction applications including: Mathematical models of curiosity; Human perceptions of curious robot behaviors; Autonomous generation of curious robot behaviors; Asking for help; Robot perception for curiosity-driven learning.
The findings by the UW team from the threads developed into the capstone demonstration, A curious robot photographer.
Understanding human perceptions toward curious robot behaviors
How do humans perceive and react to curious robots? In what situations and contexts do humans attribute curiosity to robot behaviors? In what cases is robot curiosity desirable? The UW team proposes a belief-space representation of the world, in which robots maintain a belief (distribution over hypotheses) over the unknowns, as a mathematically elegant way to capture curiosity.
To this end, the work involved the formalization of curiosity-driven exploration as Bayesian Reinforcement Learning (BRL). The UW team developed Bayesian Policy Optimization (BPO), a BRL algorithm that improves over standard policy gradient methods which do not utilize belief representations, as curiosity is emergent in the behavior of a BPO agent. Further, the scalability of BPO is improved by leveraging an ensemble of experts with the Bayesian Residual Policy Optimization (BRPO) algorithm. BRPO is shown to quickly solve a wide range of tasks including real-world navigation within a crowd of adversarial agents. The BRPO agent significantly improves from a simple ensemble and transfers to physical experiments. In the framework, curious actions result in better task inference. Since better task inference leads to better long-term rewards, the robot learns to take these actions even though the immediate cost is high.
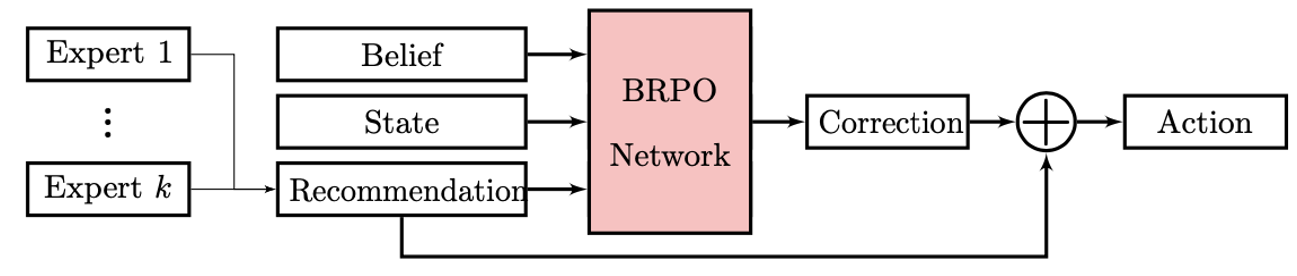
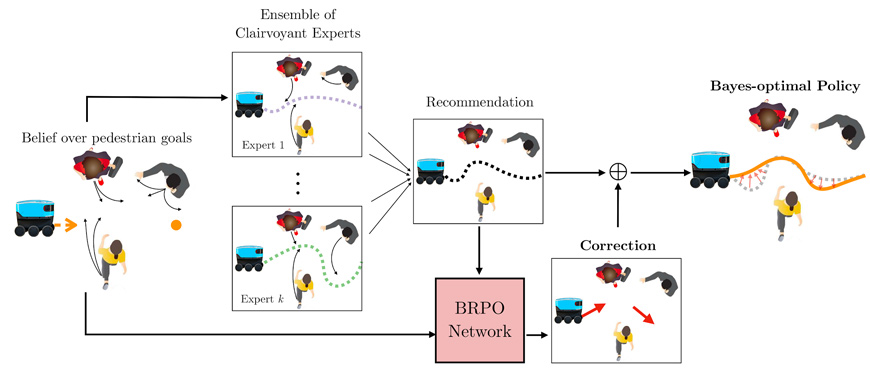
Publications:
G. Lee, B. Hou, A. Mandalika, J. Lee, S. Choudhury, and S. S. Srinivasa, “Bayesian Policy Optimization for Model Uncertainty,” In Proceedings of the International Conference on Learning Representations (ICLR), 2019.
G. Lee, B. Hou, S. Choudhury, and S. S. Srinivasa, “Bayesian Residual Policy Optimization: Scalable Bayesian Reinforcement Learning with Clairvoyant Experts,” in Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021.
Human perceptions of curious robot behaviors
Curiosity is not an entirely internal process. It has external behaviors that facilitate interactions with other agents (e.g., teachers, peers). People use behavioral cues to recognize curiosity in others and determine how/if they want to engage with them. However, past research on human curiosity makes it clear that context, as well as the relationship between a curious person and others around them, is paramount to appropriateness of curiosity. The good news is that curious behaviors seem to prime belief that a robot has complex mental states and learning capability. In other words, for humans, curiosity in robots is probably as easily recognizable as it is in other people.
The UW team did extensive work on understanding what robot behaviors are interpreted as curious by human observers, and under which conditions such behaviors are positively perceived. One of the highlights in our explorations was the study of Walker et al. which showed that when a robot deviates from its task, it can be perceived as curious. However, this might lead to negative perceptions of the robot’s competence. When the robot explains or acknowledges its deviation from the primary task, this can partially mitigate the negative effects of off-task actions. These findings motivated further studies, which went deeper into understanding the range of positively perceived robot curiosity. Leveraging help from an experienced animator, the studies investigated the connection between the level of curiosity in a robot’s behavior and human perceptions.
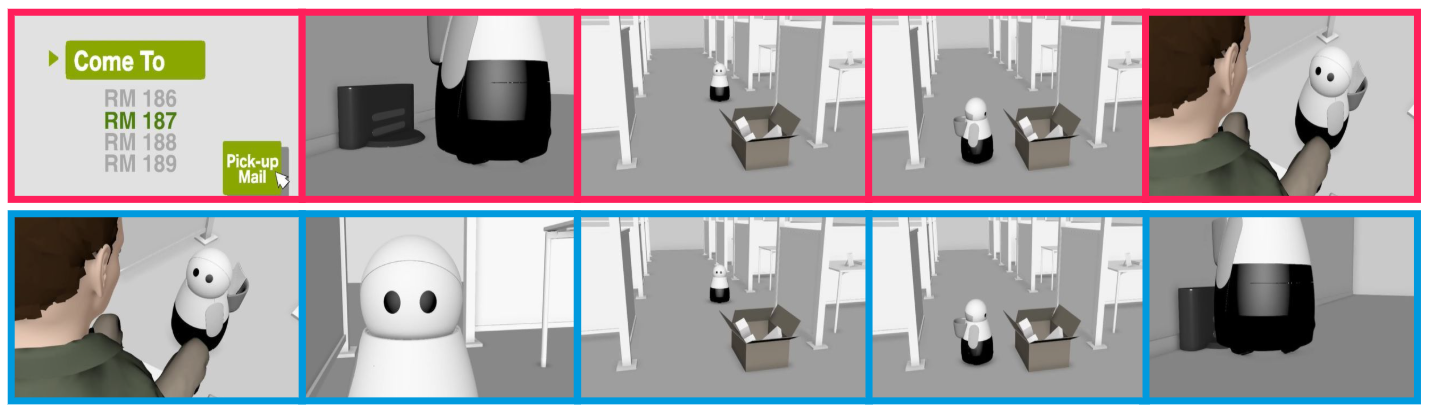

Autonomous generation of curious robot behaviors
Motivated by the studies on understanding when robots’ behaviors are perceived as curious, the UW team followed up with a planning framework for automatically synthesizing robot behaviors with the aim of eliciting curiosity attributions from human observers. The framework is an optimization-based planner that leverages a learned model of curiosity attributions to robot trajectories. Through an extensive user study and considering a coverage task, we verified that our framework may generate trajectories that are perceived as curious and showed that this finding transfers across different domains.
The figure is from the study examining human perceptions of robot trajectories in household domains with the goal of learning models of curiosity attribution to robot motion. The ultimate goal is to use such models to autonomously generate robot behaviors that will be perceived as curious by humans.
Publications:
N. Walker, C. Mavrogiannis, S. S. Srinivasa, and M. Cakmak, “Influencing Behavioral Attributions to Robot Motion During Task Execution,” In Proceedings of the ICRA Workshop on Modern Approaches for Intrinsically Motivated Intelligent Behavior, 2021.
N. Walker, C. Mavrogiannis, S. S. Srinivasa, and M. Cakmak, “Influencing Behavioral Attributions to Robot Motion During Task Execution,” in Proceedings of the Conference on Robot Learning (CoRL), 2022.
Asking for help
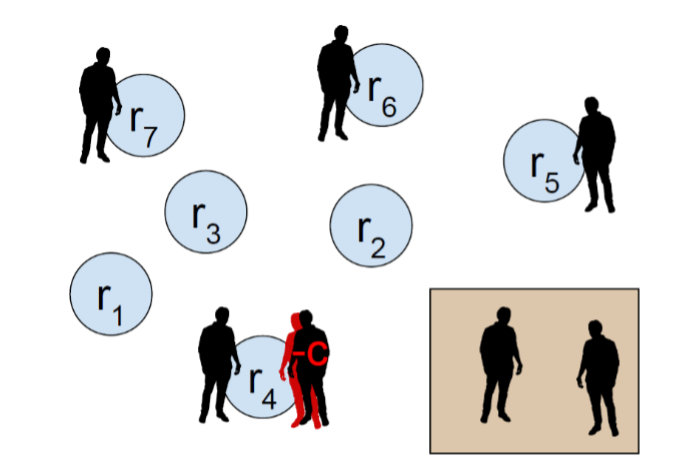
A natural way in which curiosity manifests itself in humans is through asking questions. Inspired by this observation, the UW team focused on a scenario in which a robot asks for help from human bystanders to reach a desired destination in a workplace environment. Given the lifelong aspect of such a setting, the robot needs to carefully decide when to bother bystanders to ensure long-term help from them while meeting its objectives. To tackle this problem, a model of human help is learnt, accounting for individual (latent helpfulness) and contextual factors (e.g., business, frequency of help queries) and introduced it into a BAMDP (Bayes-Adaptive Markov Decision Process) policy. The model outperformed a set of baselines while capturing positive impressions from human users.
The online virtual office environment was used to run user studies about an office robot asking a human bystander (another office employee) for help. The project explored three factors related to curiosity; 1) Laying the Foundation for Curiously Asking for Help; 2) Factors that influence Human Perception of Curiosity; 3) Robot curiously learning about the humans.
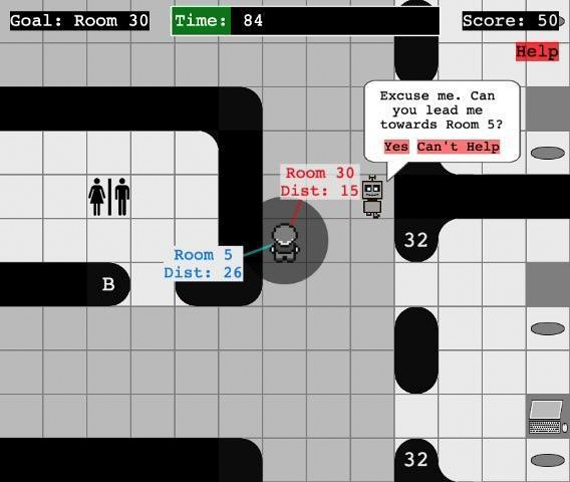
Publication:
A. Nanavati, C. Mavrogiannis, K. Weatherwax, L. Takayama, M. Cakmak, and S.S. Srinivasa, “Modeling Human Helpfulness with Individual and Contextual Factors for Robot Planning,” In Proceedings of the Robotics: Science and Systems (RSS), 2021.
Robot perception for curiosity-driven learning
Curiously exploring a human environment often entails reasoning about unseen objects and their physical properties. The UW team has been developing important components for robot perception that enable curiosity-driven learning of novel tasks in human environments. These include models for segmentation of previously unseen objects; models for pose and state estimation; and models for world dynamics applicable to manipulation tasks such as dirt cleaning.
Models for segmentation of previously unseen objects
A fundamental building block toward realizing a curiosity-driven robot is a perception system capable of identifying and isolating potentially unseen objects in an arbitrary unstructured environment. The UW team proposed a two-stage network architecture called UOIS-Net that separately leverages the strengths of RGB and depth for UOIS (Unseen Object Instance Segmentation).
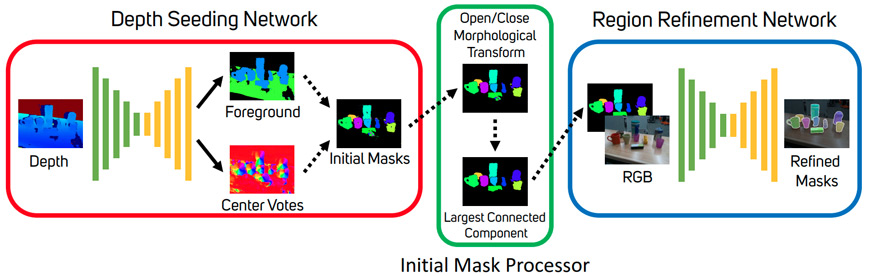
Publication:
C. Xie, Y. Xiang, A. Mousavian, and D. Fox, “Unseen Object Instance Segmentation for Robotic Environments,” In IEEE Transactions on Robotics – T-RO, 2021.
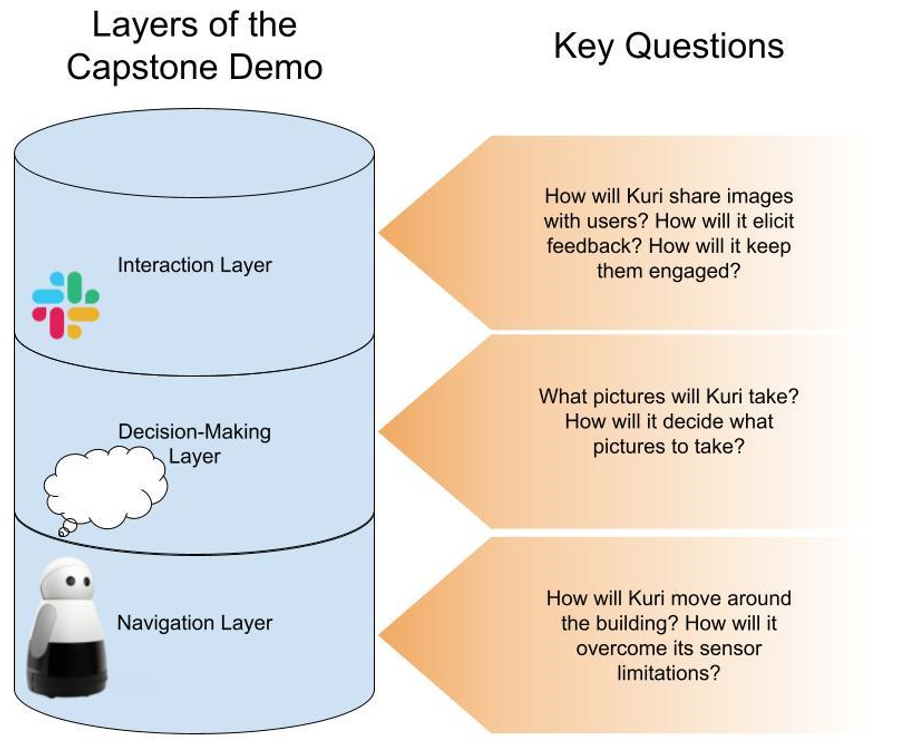
Capstone Demonstration: A curious robot photographer
The UW team’s findings from the prior threads motivated their demo project which focused on the deployment of a robot that curiously interacts with human bystanders to learn about their preferences over photo themes. The UW/UCSC Capstone demo focuses on the development of an interactive curious robot photographer. The team considers a mobile robot navigating in a real-world environment, curiously taking photos of themes it thinks people will like. The robot shares these photos over the web to remote human bystanders and gets feedback from them. Based on this feedback, the robot adapts its photo themes to human preferences. These preferences could be motivated by personal human interests (e.g., photos of plants) or by individual responsibilities (e.g., a building manager would need to monitor who enters the building). This setting allowed the team to explore a variety of research questions related to curiosity and its value in human-robot interaction;
- Does curiosity provide a navigational benefit to robots with low sensor capabilities?
- How do we design learning systems that enable a robot to curiously learn human preferences?
- How do users perceive a curious robot that interacts with them through asynchronous remote communications?
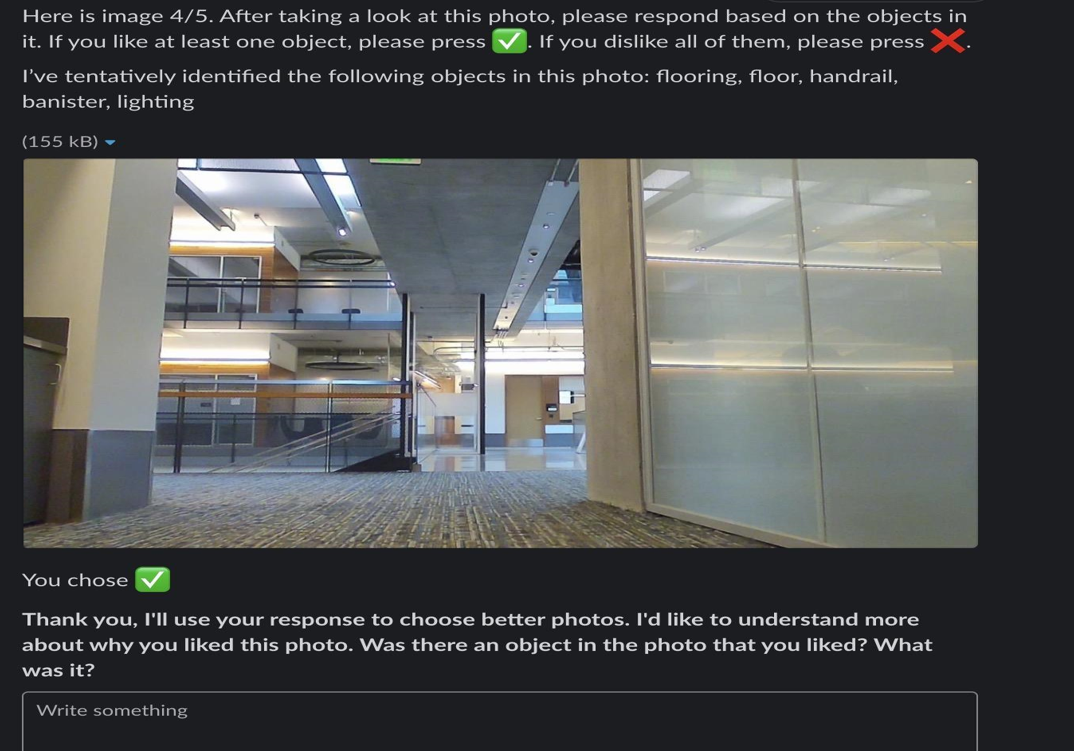
The team deployed a mobile robot (Kuri) in an academic building at UW. Connected to the department’s Slack workspace, the robot autonomously learned about the photo preferences of the users while autonomously covering a floor of about 28,000 sq. ft. over a period of 4 days. In doing so, the robot leveraged an interaction design featuring curious personality traits extracted through the insights of the team’s explorations throughout CMM. The robot was indeed perceived as curious while we found that curiosity –among other benefits—enabled the robot to get followup information from users more effectively.
Through the culmination of the team’s efforts on human perception of curiosity in robots, curiously asking for help, user-feedback, and curiosity as an emergent Bayesian phenomenon, lead to the following implications.
- Curiosity can help a robot get follow-up information.
- Curious follow-ups may elicit targeted responses, valuable for learning techniques.
- Curiosity as a design principle that enhances robot performance.
- A complete system for HRI studies/benchmarking.

The University of Pennsylvania defines curiosity as the drive to undertake actions that will result in decreasing the uncertainty in the world model. The focus of research was on representations of the perceptual stimuli suitable for curiosity and modeling of the intrinsic rewards. The two main challenges are to be able to predict, and to have a good representation of surprise that will best balance the spectrum between a completely unpredictable and a completely controlled environment. Over the course of three years, the UPenn team produced several prediction models and explored the computation of surprise.
Read More
Prediction as inpainting
The UPenn team applied the curiosity learning framework to predict affordance in a still image. Perceiving affordances – the opportunities of interaction in a scene is a fundamental ability of humans. It is an equally important skill for AI agents and robots to better understand and interact with the world. However, labeling affordances in the environment is not a trivial task. A task-agnostic framework, Inpaint2Learn, to address this issue that generates affordance labels in a fully automatic manner. A data preprocessing pipeline removes an object/person of interest from the image by obtaining its instance segmentation mask, cutting it out and filling the hole with image inpainting technique.
Publications:
L. Zhang, W. Du, S. Zhou, J. Wang, and J. Shi, “Inpaint2Learn: A Self-Supervised Framework for Affordance Learning,” In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2022.
L. Zhang, T. Wen, J. Min, J. Wang, D. Han, and J. Shi, “Learning Object Placement by Inpainting for Compositional Data Augmentation,” In Computer Vision - ECCV 2020. Springer International Publishing, 2020.
Generative models for prediction
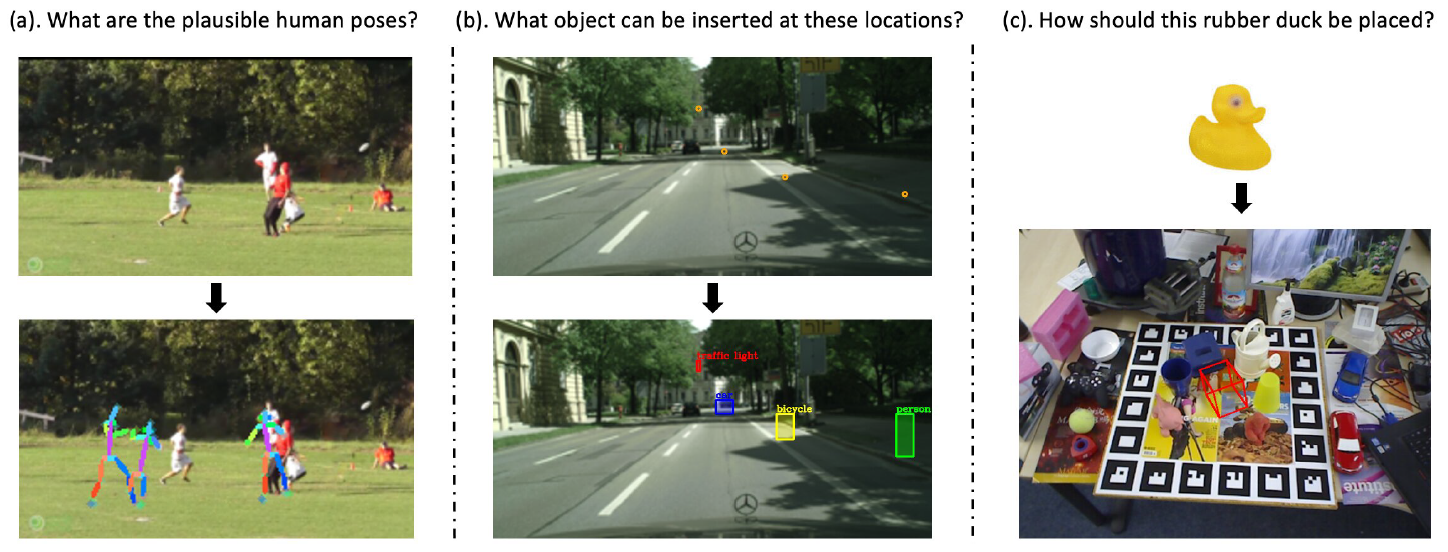
In order to help agents quickly learn to predict the effects of their own actions on the environment and to plan complex action sequences, the agents need to learn an action space of a robot, as well as a predictive model of observations given actions. The UPenn team studied the full model with composable action representations Composable Learned Action Space Predictor (CLASP) and showed the applicability of the method to synthetic settings and its potential to capture action spaces in complex, realistic visual settings.
Publications:
O. Rybkin, K. Pertsch, K. G. Derpanis, K. Daniilidis, and A. Jaegle, "Learning what you can do before doing anything," In Proceedings of the International Conference on Learning Representations (ICLR), 2019.
O. Rybkin, K. Daniilidis, and S. Levine, “Simple and Effective VAE Training with Calibrated Decoders,” In Proceedings of the International Conference of Machine Learning (ICML), 2021.
Object-centric prediction
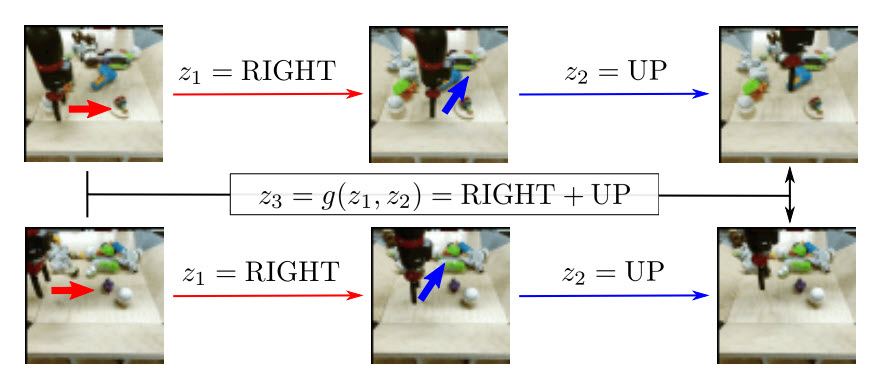
Curiosity drives agents towards interesting parts of the environment, but the model of the world is required for developing curious behavior. In order to interact with the world, agents need predictive model that encodes dynamics and object-to-object interaction. The UPenn team came with an Object-centric video prediction framework that takes advantage of the simple prior that the world is made of objects and by providing a more natural interface for control. However, existing object-centric video prediction pipelines require dense object annotations in training video sequences. Object-centric Prediction without Annotation (OPA) is an object-centric video prediction method that takes advantage of priors from powerful computer vision models. It has been validated on a dataset comprised of video sequences of stacked objects falling and demonstrated how to adapt a perception model in an environment through end-to-end video prediction training.
Publication:
K. Schmeckpeper, G. Georgakis, and K. Daniilidis, “Object-Centric Video Prediction without Annotation,” In Proceedings of the International Conference of Robotics and Automation (ICRA), 2021.
Visual reasoning for robotics
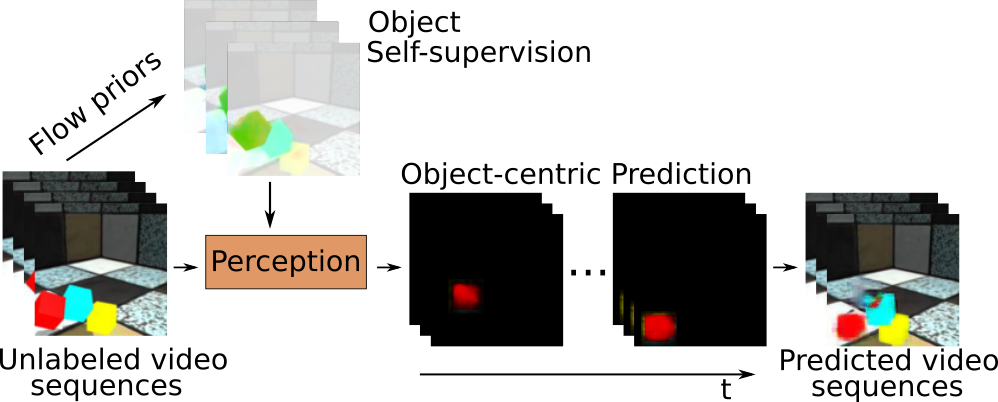
Given an observation of the environment, humans can hallucinate diverse and plausible locations for an object to exist and action goals to achieve. To learn a generative model that can densely predict diverse and plausible states, the UPenn team proposed to first learn a generative model to unfold a canonical conditional input, and then learn another network to deform the canonical solutions conditioned on a new environment. In the synthetic experimental setting, the team found out that the method can produce much coverage of solution spaces than baselines.

Publication:
L. Zhang, S. Zhou, and J. Shi, “Predicting Diverse and Plausible State Foresight For Robotic Pushing Tasks,” In RSS workshop on Visual Learning and Reasoning for Robotic Manipulation (VLRRM), 2020.
Adversarial Curiosity
The University of Pennsylvania team continued its work on adversarial curiosity approach which actively samples data to train a prediction model where they use a discriminator score as novelty. The model-based curiosity combines active learning approaches to optimal sampling with the information gain-based incentives for exploration presented in the curiosity literature. The experiments demonstrate progressively increasing advantages of the adversarial curiosity approach over leading model-based exploration strategies, when computational resources are restricted. The team further demonstrated the ability of the adversarial curiosity method to scale to a robotic manipulation, and observed that curiosity increases object interactions, helps explore interesting areas, and improves predictive model performance.
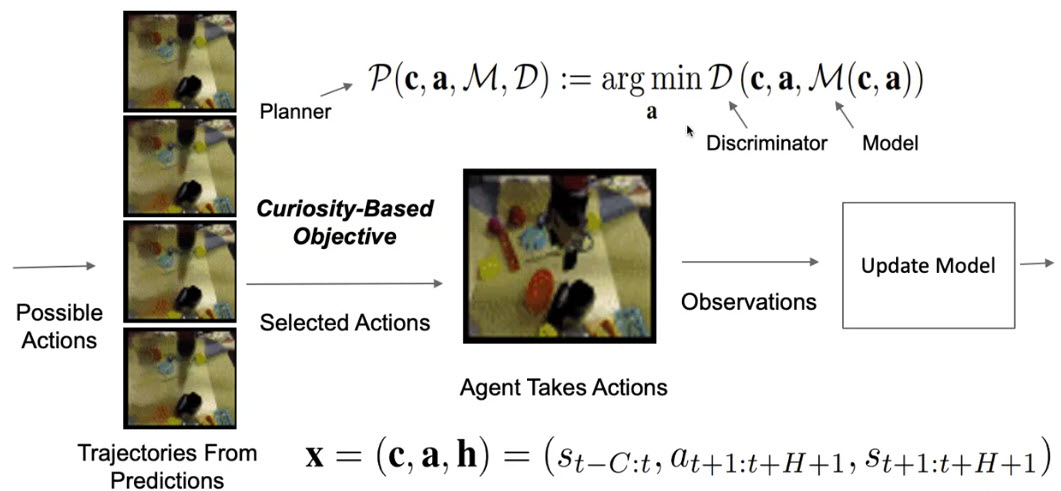
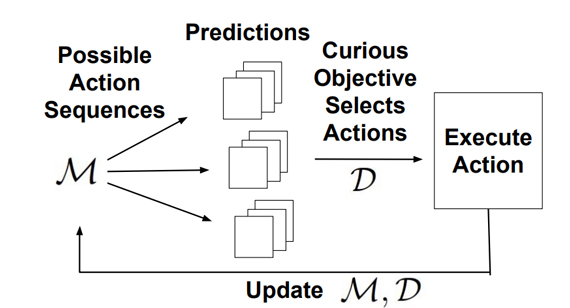
Publications:
B. Bucher, K. Schmeckpeper, N. Matni, and K. Daniilidis, ”An Adversarial Objective for Scalable Exploration,” in Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2021.
B. Bucher, A. Arapin, R. Sekar, F. Duan, M. Badger , K. Daniilidis, and O. Rybkin. “Perception-Driven Curiosity with Bayesian Surprise,” In RSS Workshop on Combining Learning and Reasoning Towards Human-Level Robot Intelligence, 2019.
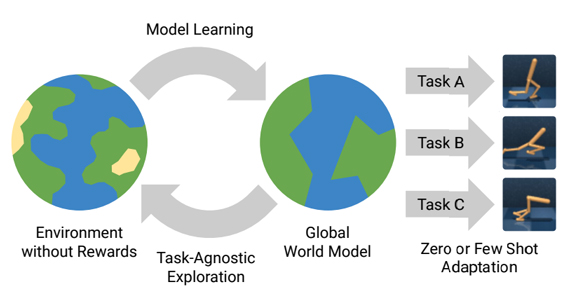
Plan to Explore (Plan2Explore)
Exploring and learning the world model without rewards, the team used the disagreement of latent representations as novelty. In this approach, latent disagreement (LD), efficiently adapts to a range of control tasks with high-dimensional image inputs. While current methods often learn reactive exploration behaviors to maximize retrospective novelty, we learn a world model trained from images to plan for expected surprise. To explore complex environments with high-dimensional inputs in the absence of rewards, the agent needs to follow a form of intrinsic motivation or curiosity.
The key ideas of Plan2Explore are to use long-term planning with the world model to explore the environment, collecting novel data to train the model to further improve exploration. The same model is later used to plan for new tasks at test times.
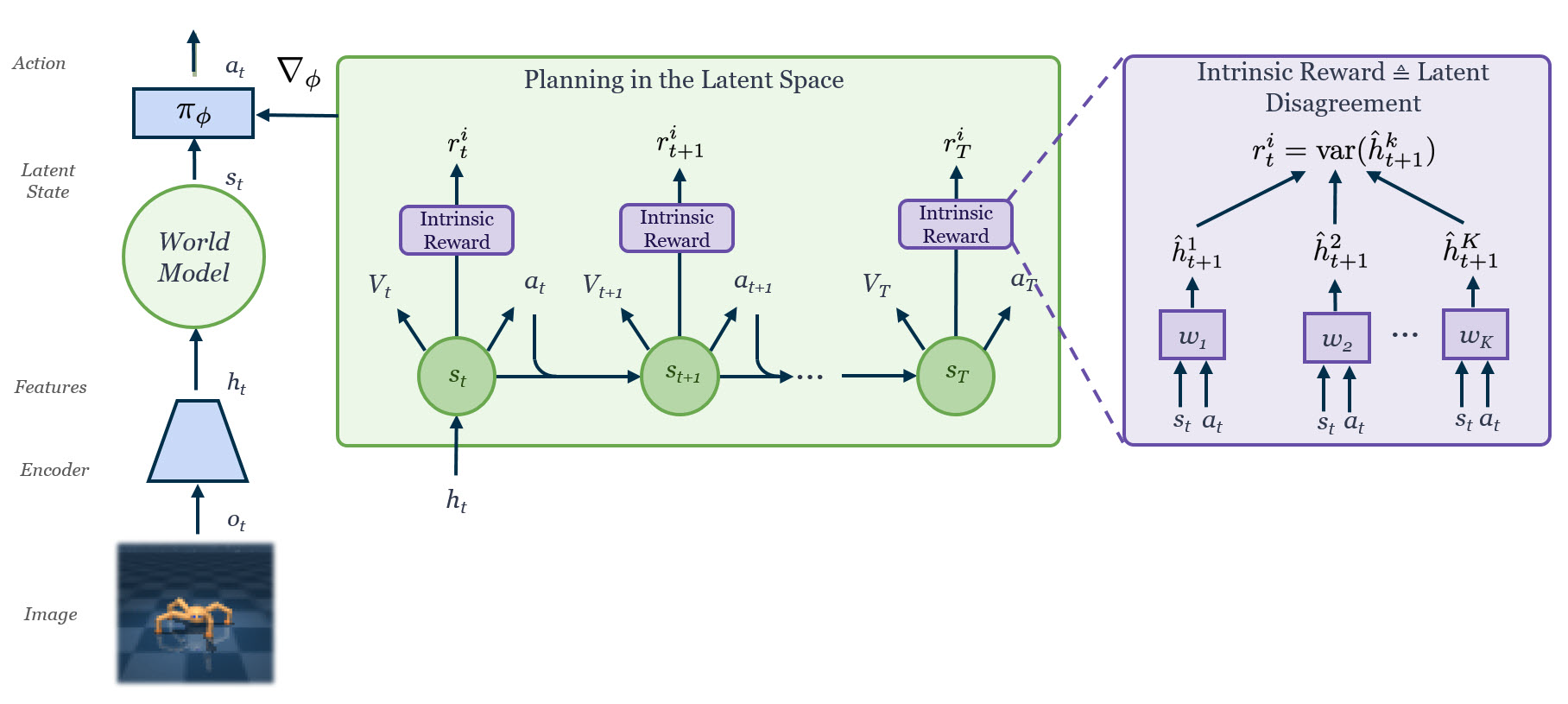
Publication:
R. Sekar, O. Rybkin, K. Daniilidis, P. Abbeel, D. Hafner, and D. Pathak, “Planning to explore via self-supervised world models,” In Proceedings of the International Conference of Machine Learning (ICML), 2020.
Learning to Map with Curiosity
A curious explorer needs to learn to map an environment and find objects. The UPenn team considered the problem of object goal navigation in unseen environments. The Learning to Map (L2M) approach involves learning a mapping model than can predict (hallucinate) semantics in unobserved regions of the map containing both objects (e.g. chairs, beds) and structures (e.g. door, wall), and during testing uses the uncertainty over these predictions to plan a path towards the target. Contrary to traditional approaches for mapping and navigation problems (i.e. SLAM) where the focus is on building accurate 3D metric maps, our uncertainty formulation is designed to capture our lack of confidence about whether a certain object exists at a particular location. This results in a much more meaningful representation, suitable for target-driven tasks.

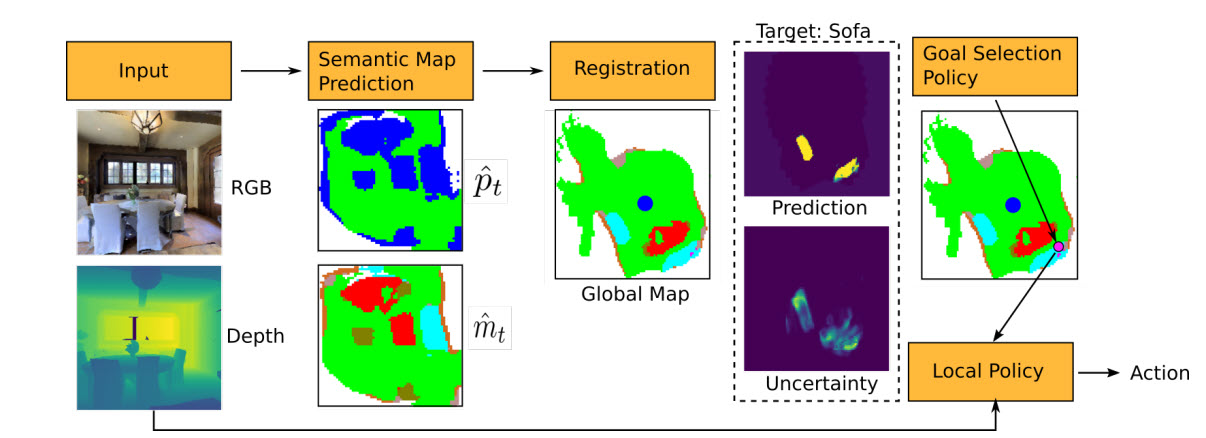


Publication:
G. Georgakis*, B. Bucher*, K. Schmeckpeper, S. Singh, and K. Daniilidis. “Learning to Map for Active Semantic Goal Navigation,” In Proceedings of the International Conference on Learning Representations (ICLR), 2022.
Curious exploration in complex environments
UPenn team approached the question of curiosity by comparing reinforcement learning agents using different phenomenological models of curiosity in environments of controlled complexity. The team found that indeed, greedy agents are inferior to curious ones in certain complex environments. However, when environments are too complex or noisy, curiosity imparts no benefit. These findings imply that curiosity is useful in a window of intermediate environmental complexity.
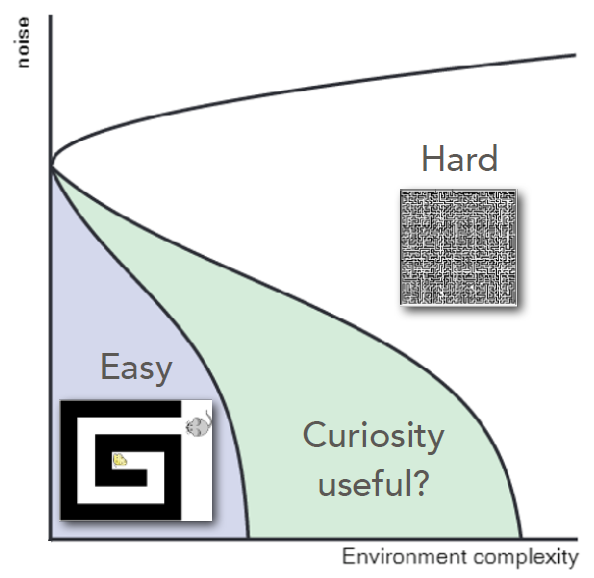
Publications:
M. Stern, C. D. Mulatier, P. Fleig, and V. Balasubramanian, "Curious exploration in complex environments," Bulletin of the American Physical Society, 2021.
B. Bucher, S. Singh, C. D. Mulatier, K. Daniilidis, and V. Balasubramanian, “Curiosity increases equality in competitive resource allocation,” In ICLR Workshop on Bridging AI and Cognitive Science 15 (BAICS), 2020.
The MIT team refined the definition of Curiosity as:
The algorithmic machinery that enables a robot to deal with the unexpected, by training lifelong not just to solve the immediate task at hand but to interact with the world so that it can develop knowledge that will possibly help the robot in the future.
The team’s projects are focused on the notion that any intelligent agent must have a causal theory of the world that can be used to reason about sensor data, predict future percepts and predict the effects of future actions; essentially, a theory of “how the world works.” Over the three-year period, the MIT team developed a theory of how a period of “curious” but directed interaction with mechanisms can lead to the ability to actuate never-before-seen mechanisms, and curious learning algorithms which can learn a model of complex operations that allows the robot to quickly solve complex tasks. It was shown that curiosity is most effective when the system has an explicit parameterization of the world, in terms of states, action dynamics, sensor model, etc., in contrast to model-free learning techniques. In MIT’s capstone demonstration, the researchers confirmed that a curious robot learning performs better than an incurious robot at building complicated towers out of blocks with unusual physical properties.
Read More
Curious Model Learning
Curious exploration via subgoal generation can result in models (both kinematic and causal/symbolic) that capture aspects of the environment which are general and useful in future more difficult tasks. The MIT team is focusing its research on learning models of objects in the environment.
Learning to Manipulate a Novel Object
Humans are able to manipulate novel objects without prior experience on the specific object and the goal is to transfer a knowledge of a controller which is rooted in vision. The MIT team developed a theory of how a period of “curious” but directed interaction with mechanisms can lead to the ability to actuate never-before-seen mechanisms instances with very few (sometimes just one) trials.
Publication:
C. Moses, M. Noseworthy, L.P. Kaelbling, T. Lozano-Pérez, and N. Roy, “Visual Prediction of Priors for Articulated Object Interaction,” In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2020.
Synthesis-Based Curiosity for Learning Compositional Dynamics
The goal is to enable a robot to efficiently interact with novel objects with unusual dynamics, where the robot can learn the impact of the unusual dynamics from previous visuo-motor experience with related objects without human guidance.
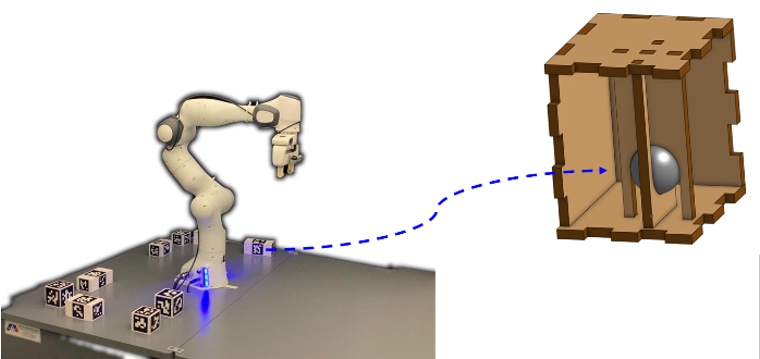
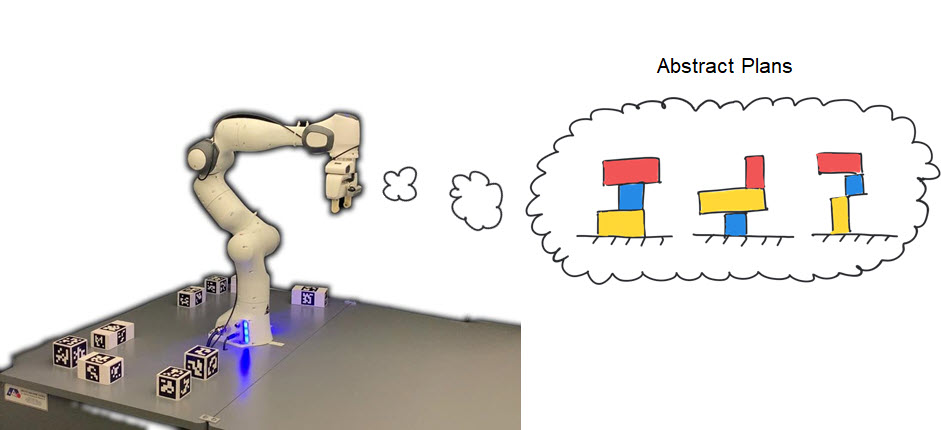
Publications:
C. Moses, M. Noseworthy, L.P. Kaelbling, T. Lozano-Pérez, and N. Roy, “Visual Prediction of Priors for Articulated Object Interaction,” In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2020.
M. Noseworthy, C. Moses, I . Brand, S. Castro, L. Kaelbling, T. Lozano-Pérez and N. Roy, “Active Learning of Abstract Plan Feasibility,” In Proceedings of the Robotics Science and Systems (RSS), 2021.
Compositional Skill Learning through Curiosity-Driven Compilation of Hierarchical Policies
Curiosity-driven exploration means to explore parts of the environment about which we do not know. The MIT team hypothesizes that a curious agent should, when faced with a set of training settings that do not have extrinsic goals/rewards, learn useful high-level policies that can be composed in various ways through planning, in order to succeed quickly at longer-horizon tasks (i.e. sample-efficiently, with very little adaptation or data for this new task).
Goal-Literal Babbling
In pursuit of an exploration strategy that can drive an agent toward interesting regions of the state space, the team proposed a novel family of exploration methods for relational transition model learning called Goal-Literal Babbling (GLIB).
Learning Symbolic Operators for Task and Motion Planning (TAMP)
The team worked on the problem of operator learning that can be composed to enable efficient planning and task execution on future tasks in future environments. In particular, the approach can be understood as a model-based method for learning guidance in hybrid planning problems: the operators define an abstract transition model that provides guidance. The operators in TAMP, therefore, are useful in that they give guidance to the overall planning procedure -- being able to efficiently learn operators is the goal of a curious machine.
Publications:
R. Chitnis, T. Silver, J. Tenenbaum, L. Kaelbling and T. Lozano-Pérez. “GLIB: Efficient Exploration for Relational Model-Based Reinforcement Learning via Goal-Literal Babbling,” In Proceedings of the National Conference on Artificial Intelligence (AAAI), 2021.
T. Silver, R. Chitnis, J. Tenenbaum, L. Kaelbling and T. Lozano-Pérez, “Learning Symbolic Operators for Task and Motion Planning,” In Proceedings of the IEEE/RSJ International Conference on Intelligent Robot Systems (IROS), 2021.
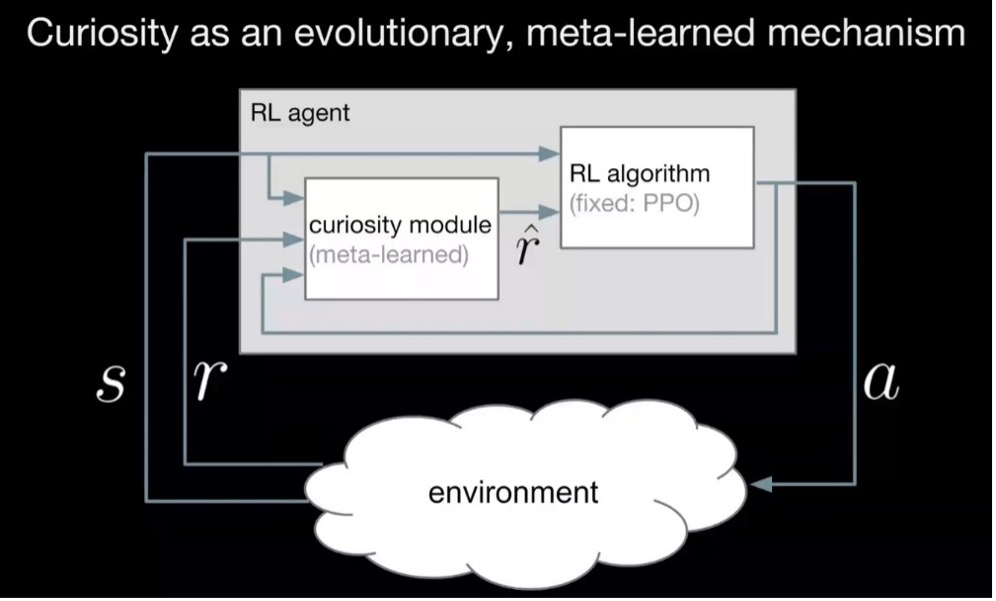
Meta-Learning Curiosity Algorithms
Proper exploration is critical to make reinforcement learning data-efficient, and a lot of effort has been devoted to develop algorithms that elicit curious behavior in complex environments as well as algorithms that trade off between exploration and exploitation in bandit settings. However, we still lack an exploration algorithm that generalizes well between very different environments: The MIT team aims to find a curiosity module that achieves high total long-term reward in many different environments. They hypothesize that curiosity is an evolutionary-found system that encourages meaningful exploration in order to get high long-term reward and propose to frame this evolutionary search in algorithm space.
The team is investigating in formulating the problem of generating curious behavior as one of meta-learning. The team aims at generalization between completely different environments, even between environments that do not share the same I/O spec. It is done by transferring algorithms rather than network policies or features. To explore the space of reward combing programs, the team ran experiments on a range of virtual tasks from landing a moon rover to raising a robotic arm and moving an ant-like robot in a physical simulation. The top 16 discovered algorithms performed as well as human-designed algorithms and were variations of two novel algorithms.

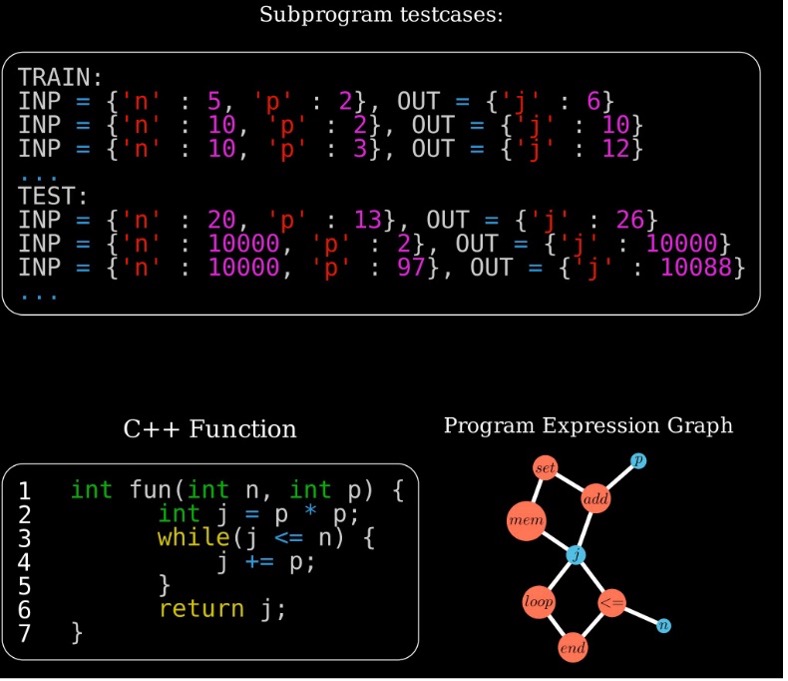
A key to meta-learning is generalization, and programs often provide extreme generalization capabilities from surprisingly few examples; however, the combinatorial space of programs has proven hard to search. Curiosity-driven models can be used to learn to search more efficiently, but to train such systems we need a dataset of program induction tasks. The team has developed a new way of leveraging a collection of programs with associated unit tests to create a much larger collection of test-program pairs, which lead to a creation of PROGRES (Programs from Real Executed Subproblems), a large-scale naturalistic few-shot program-induction benchmark of real programs.
Publications:
F. Alet, M. Schneider, T. Lozano-Perez, and L. P. Kaelbling, “Meta-learning curiosity algorithms,” In Proceedings of the International Conference on Learning Representations (ICLR), 2020.
F. Alet, J. Lopez-Contreras, J. Koppel, M. Nye, A. Solar-Lezama, T. Lozano-Perez, L. Kaelbling and J. Tenenbaum, “A large-scale benchmark for few-shot program induction and synthesis,” In Proceedings of the International Conference on Machine Learning (ICML), 2021.
F. Alet, D. Doblar, A. Zhou, J. Tenenbaum, K. Kawaguchi and C. Finn. “Noether Networks: meta-learning useful conserved quantities,” In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), 2021.
Learning Universal Curiosity
In pursuit of curious artificial agents, the MIT team takes an approach where agents that are curious in a particular way survives over many trials where less or differently curious agent do not. The MIT team proposes to create many agents in many environments with many different variations of curiosity; adapt over many generations to arrive at one implementation of curiosity that is universally beneficial in a given distribution of environments. An intrinsic reward function is typically hand-designed and used to guide exploration within a single reinforcement learning task. The team instead proposes to learn an intrinsic reward that works across many tasks.
The MIT team will test the hypothesis that curiosity is driven by an intrinsic reward function that can be learned from heuristic reward functions that are externally encoded, and the intrinsic reward function has internal structure encoded as sub-goals.
The team studied human creative tool use, focusing on understanding both what is learned during performance, and what people think is important to learn. The human is found to learn relational programmatic strategies from only trial-and-error experience, and they persistently apply to new tasks. The extended SSUP model aligns with this behavior. The experiment has been extended to people with limb differences and the team developed a visual and physical prediction simulation benchmark that precisely measures this prediction capability.
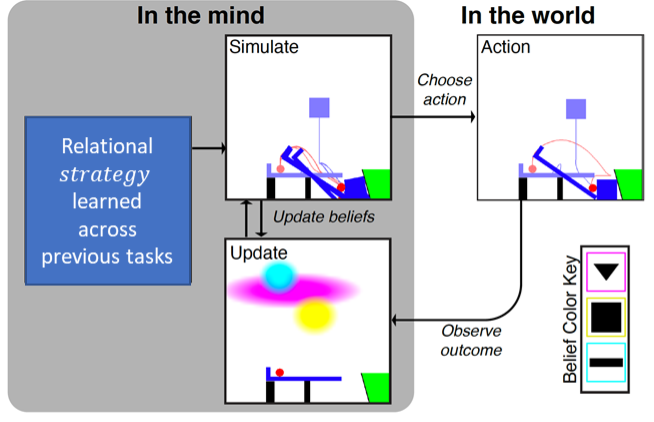
Publication:
K. R. Allen, K. A. Smith, L.-A. Bird, J. B. Tenenbaum, T. R. Makin, and D. Cowie, “Meta-strategy learning in physical problem-solving: The effect of embodied experience,” BioRxiv, 2021.07.08.451333, 2021.
Capstone Demonstration: A curious robot builder
The MIT/Penn/UW Capstone demo focuses on the development of an interactive curious robot that learns how to build complex structures. We consider a manipulator presented with a series of solids that have unusual dynamics, such as uneven centres of mass, unexpected adhesion properties or unusual kinematic properties.
This demonstration uses the Panda robot from Franka, a single arm fixed manipulator. The objects the robot interacts with have different mass distributions which are created by 3D printing blocks with interior mounts f or added weight. Up to 3 Intel RealSense D435 cameras are currently being used for the vision pipeline. MIT curiosity-driven planning system (Noseworthy 2021) has been integrated to UPenn’s keypoint detection system UW’s DeepIM object pose estimation system.
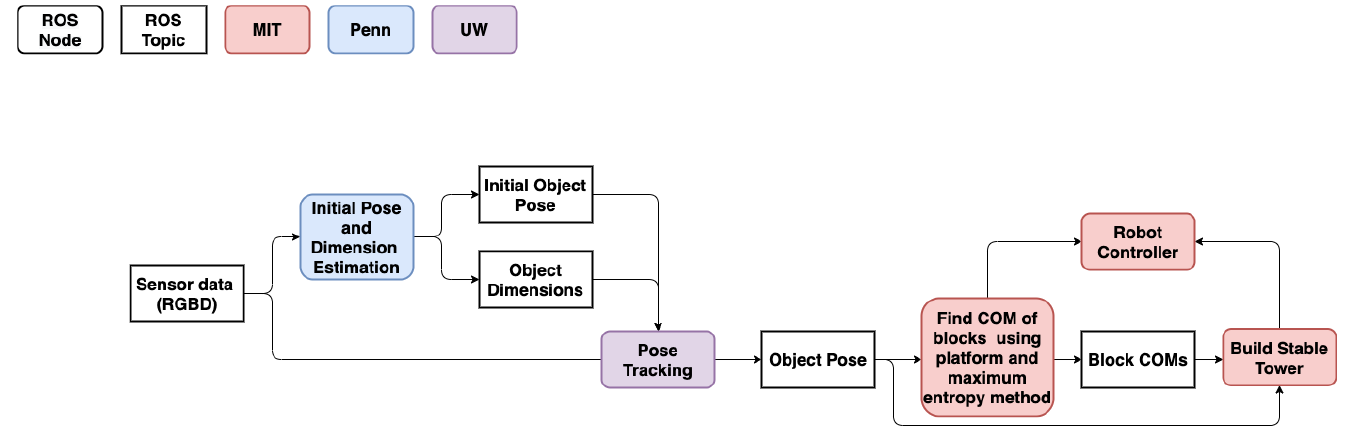
The robot has no prior information that the blocks have different mass distributions. It spends time being curious by attempting to build different structures. The planning system focuses on gathering information according to the Bayesian active learning by disagreement objective. As its construction efforts succeed and fail, it learns the properties of the blocks, and how they behave. The robot is then be given a specific task, such as build the tallest tower or build a tower with the most overhang.
The system with artificial curiosity was able to complete this task more quickly than a robot with no prior curiosity. Curiosity occurs in this experiment in how the robot interacts with the world when it does not have a task. This demonstration shows that the curious exploration will result in more efficient completion of novel tasks. Additionally, the demonstration shows that our specific mathematical theory of curiosity is more effective than other possible approaches.
Publication:
M. Noseworthy, C. Moses, I . Brand, S. Castro, L. Kaelbling, T. Lozano-Pérez and N. Roy, “Curiosity-Driven Learning of Abstract Plan Feasibility,” In Proceedings of ICRA Workshop, Towards Curious Robots: Modern Approaches for Intrinsically-Motivated Intelligent Behavior, 2021.