Research - Legacy Archive - HRI-CMM
Research
Since May 2018, Honda Research Institute has collaborated with research teams from Massachusetts Institute of Technology (MIT), University of Pennsylvania, and University of Washington to investigate the concept of curiosity in humans and machines.
Our ultimate goal is to create new types of machines that can acquire an interest in learning and knowledge, the ability to learn and discover, and the ability to interact with the world and others. We want to develop Curious Minded Machines that use curiosity to serve the common good by understanding people’s needs, empowering human productivity, and ultimately addressing complex societal issues.
For more information about each team’s research, click on the university logos >>
When interacting with humans, the team believes that curiosity can drive a robot to learn what might be most useful in the long term or relevant for their users, and a robot perceived as curious or inquisitive will be more acceptable to its users given its limitations, such as the inability to perform some tasks or mistakes it makes in available tasks.
The University of Washington team aims to construct a mathematical model of curiosity, and is investigating different reinforcement learning methods that aim at (a) curiosity-driven exploration and (b) safe exploration.
Read More
Bayesian Reinforcement Learning
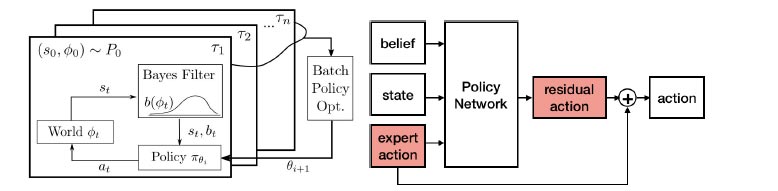
In the University of Washington team’s Bayesian reinforcement learning (BRL) framework, curious actions result in better task inference. Since better task inference leads to better long-term rewards, the robot learns to take these actions even though the immediate cost is high.
Publications:
G. Lee, B. Hou, A. Mandalika, J. Lee, S. Choudhury, S. Srinivasa. Bayesian Policy Optimization for Model Uncertainty. In International Conference on Learning Representations (ICLR), 2019.
G. Lee, S. Choudhury, B. Hou, S. Srinivasa. Bayesian Residual Policy Optimization: Scalable Bayesian Reinforcement Learning with Clairvoyant Experts. In Robotics: Science and Systems, 2020. [under review]
Safety in Imitation Learning
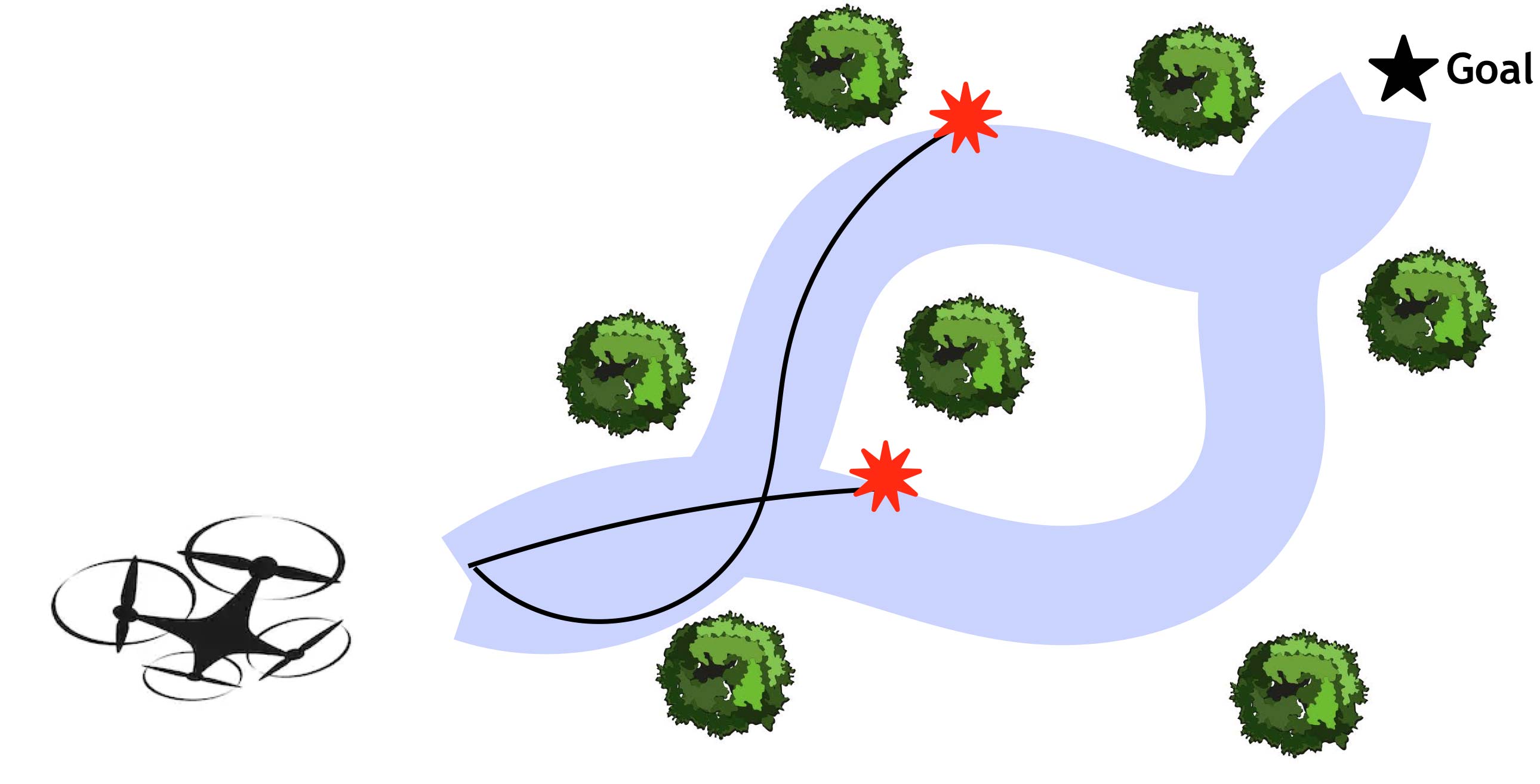
How can a robot be curious yet safe? University of Washington researchers are exploring this question in the Imitation Learning setting, where an interactive user is providing guidance to a robot learning to explore its world. The user takes over and optionally rescues the robot when it perceives an unsafe condition. The team hypothesizes that it is possible to be safely curious, by leveraging feedback from a human expert.
Publication:
S. Ainsworth, M. Barnes, and S. Srinivasa. Mo' States Mo' Problems: Emergency Stop Mechanisms from Observation. In Neural Information Processing Systems, 2019.
People’s Perception of a Curious Robot
The team is analyzing 73 parent-child interviews and survey data to understand how curiosity is viewed and conceptualized in a robot. For instance, parental difference in technology experiences may impact how parents teach children to conceptualize robots as an ambiguous ontological category straddling various levels of aliveness. This perception of what a robot inherently is (e.g., a machine/tool vs. something cognizant/alive) may alter the affordance and autonomy levels participants expect a robot to have as well as differences in preference for the way it behaves towards/around them.

Developing Perceptions of Robot Curiosity
To explore people's perception of robot curiosity, the University of Washington team is manipulating a robot's behavior in different ways to understand what might be perceived as curiosity in a robot and whether that is a preferred/likable attribute for a robot. The team is conducting an online robot observation study to look at how different durations of deviation impact perception of curiosity.
Publication:
N. Walker, K. Weatherwax, J. Alchin, L. Takayama, and M. Cakmak. Human Perceptions of a Curious Robot that Performs Off-Task Actions. In ACM/IEEE International Conference on Human-Robot Interaction (HRI), pp. 529–538, 2020.
The University of Pennsylvania defines curiosity as a strategic mode of exploration, adopted by an agent in order to maximize future rewards on tasks yet to be specified, but useless with regards to the current task(s).
Assuming that curiosity is a behavior that becomes advantageous (or even necessary for survival) in the long term, the team established a simple problem allowing them to quantify how much advantage one would get in the long term by allocating time and energy for exploring (vs non exploring). They expect that curious exploration will appear useless or necessary, depending on the complexity of the environment in which the agent is evolving.
Read More
Perception-Driven Curiosity with Bayesian Surprise
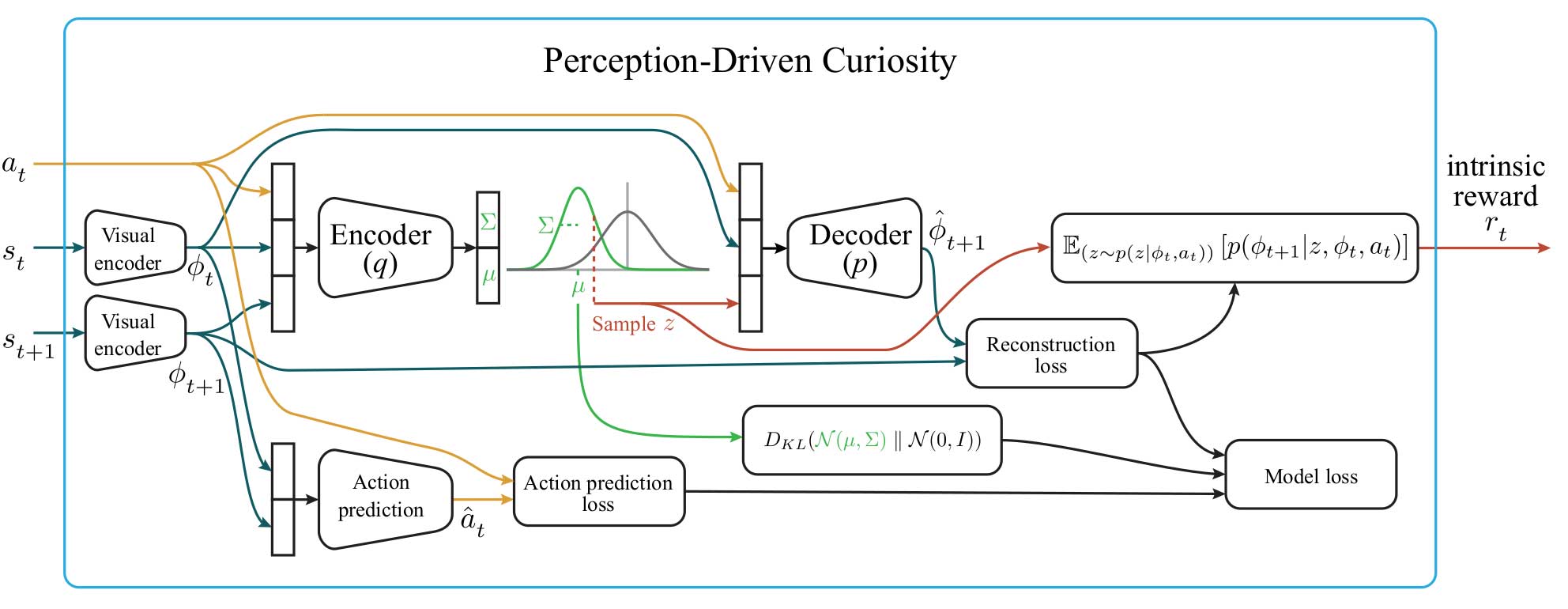
The University of Pennsylvania developed a perception model which gives a measurement of how much information an agent has retained about the visual characteristics of their environment. Prediction-driven curiosity models incorporate the ability of agents to reconstruct scenes, but they do not measure this ability separately from the environment dynamics. The team’s approach uses a learned prediction model as a constraint in perception.
Surprise is a conceptual formulation of information gain. Therefore, introducing a stochastic modeling approach to the measurement of surprise will be less brittle to environmental noise than existing approaches such as pixel-level reconstruction error.
Publication:
B. Bucher, A. Arapin, R. Sekar, F. Duan, M. Badger , K. Daniilidis, O. Rybkin. Perception-Driven Curiosity with Bayesian Surprise. In RSS Workshop on Combining Learning and Reasoning Towards Human-Level Robot Intelligence, 2019.
Semi-Supervised Action Representations
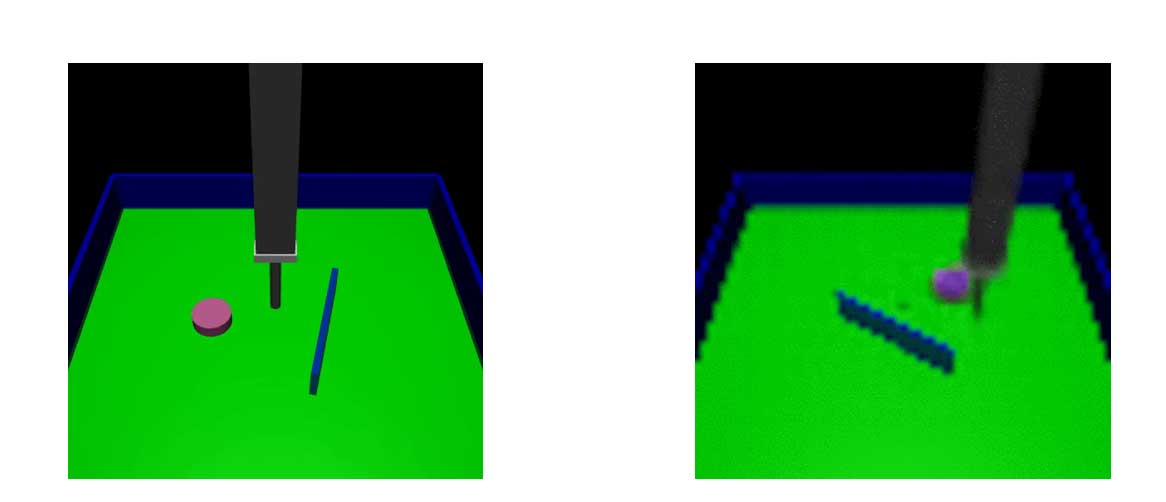
In order for the robot to perform complex tasks such as manipulation, a sufficiently precise dynamics model is necessary. The team proposes planning with learned visual predictive models to overcome the challenge of constructing analytical models with data-driven deep learning approaches. Visual planning has demonstrated success at tasks such as pushing objects, stacking blocks, and manipulating rope. These tasks require good models of contact forces, gravity, and deformability that would have been very difficult to hand design.
Publications:
O. Rybkin, K. Pertsch, K. G. Derpanis, K. Daniilidis, and A. Jaegle. Learning what you can do before doing anything. In International Conference on Learning Representations (ICLR), 2019.
K. Pertsch, O. Rybkin, J. Yang , K. G. Derpanis, J. Lim, K. Daniilidis , A. Jaegle. KeyIn: Discovering Subgoal Structure with Keyframe-based Video Prediction. In Learning for Decision and Control (L4DC), 2020.
Necessary ingredients for curiosity to emerge in spatial navigation
The University of Pennsylvania team defines curiosity as a strategic mode of exploration, adopted by an agent in order to maximize future rewards on tasks yet to be specified, but useless with regards to the current task(s). Assuming that curiosity is a behavior that becomes advantageous (or even necessary for survival) in the long term, the team set a simple problem allowing them to quantify how much advantage one would get in the long term by allocating time and energy for exploring (vs non exploring). They expect that curious exploration will appear useless or necessary, depending on the complexity of the environment in which the agent is evolving.
Publications:
L. Kang and V. Balasubramanian, A geometric attractor mechanism for self-organization of entorhinal grid modules, eLife, 2019.
B. Bucher, S. Singh, C. Mutalier, K. Daniilidis, and V. Balasubramanian. Curiosity increases equality in competitive resource allocation. In ICLR Workshop on Bridging AI and Cognitive Science (BAICS), 2020.
Normalized Diversification for First Person Vision
Normalized Diversification is an important factor of a curiosity learning, as diverse action sampling could encourage curious exploration in robotic learning, and diverse future state predictions allow us to model stochasticity or uncertainty in the robotic environment. First person video (FPV) allows one to ‘think in other’s shoes’ by experiencing actions and visual sensation from ego-centric view. The team proposes normalized diversification as a mechanism to learn an internal manifold representation from sparse data that prevents mode collapsing.
Publications:
S. Liu, X. Zhang, J.Wangni, J. Shi. Normalized Diversification. In IEEE Computer Vision Pattern Recognition, 2019.
L. Zhang, J. Wang, J. Shi. Multimodal Image Outpainting With Regularized Normalized Diversification. In 2020 Winter Conference on Applications of Computer Vision (WACV ’20), 2020.
The MIT team is researching curiosity as a mechanism for acquiring a predictive theory of the world as well as examining how algorithmic science can learn from the study of developmental psychology. They also are exploring several hypotheses about how children learn, what they learn and why, by embodying these hypotheses and testing them in their Curious Minded Machines.
Read More
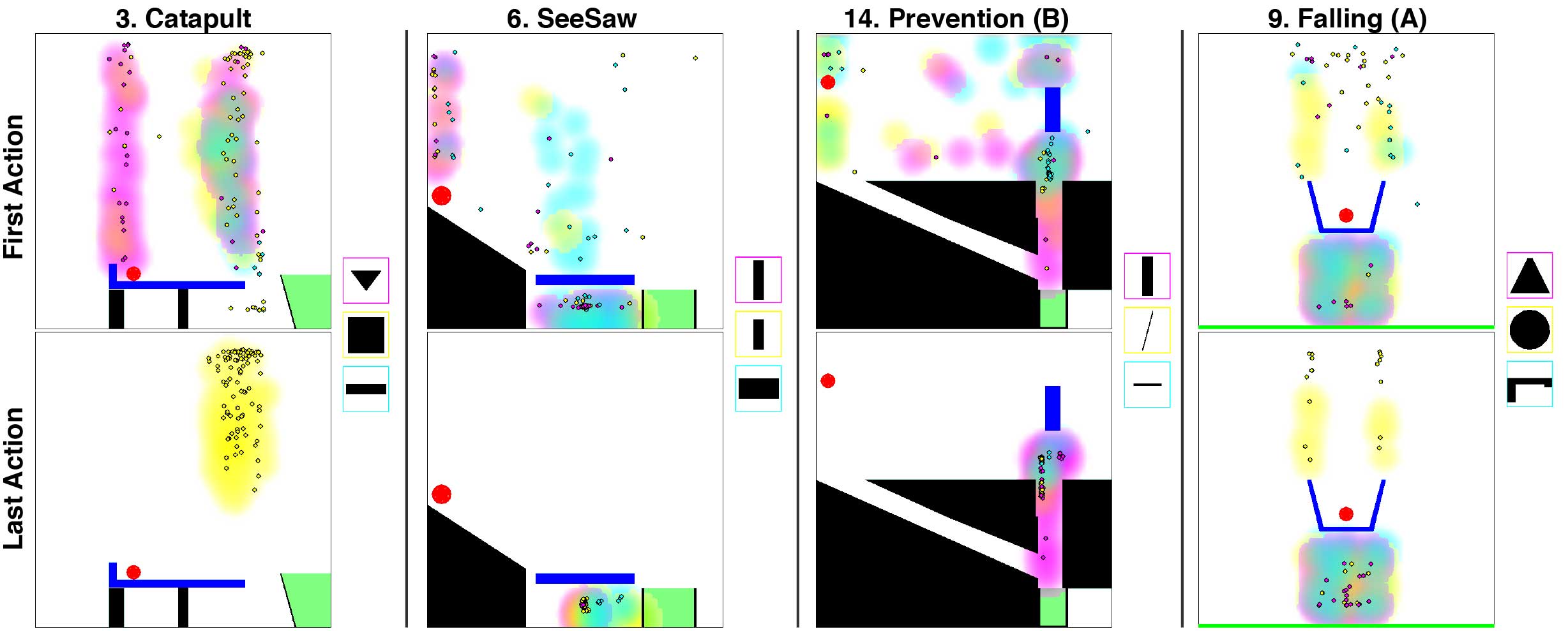
Learning Universal Curiosity
The MIT team will test the hypothesis that curiosity is driven by an intrinsic reward function that can be learned from heuristic reward functions that are externally encoded. Therefore, the intrinsic reward function has internal structure encoded as sub-goals.
Publications:
V. Xia, Z. Wang, K. Allen, T. Silver and L. P. Kaelbling. Learning sparse relational transition models. In International Conference on Learning Representations (ICLR), 2019.
K. Allen, K. Smith, and J. Tenenbaum. The Tools Challenge: Rapid Trial-and-error Learning In Physical Problem Solving. In the 41st Annual Meeting of the Cognitive Science Society, 2019.
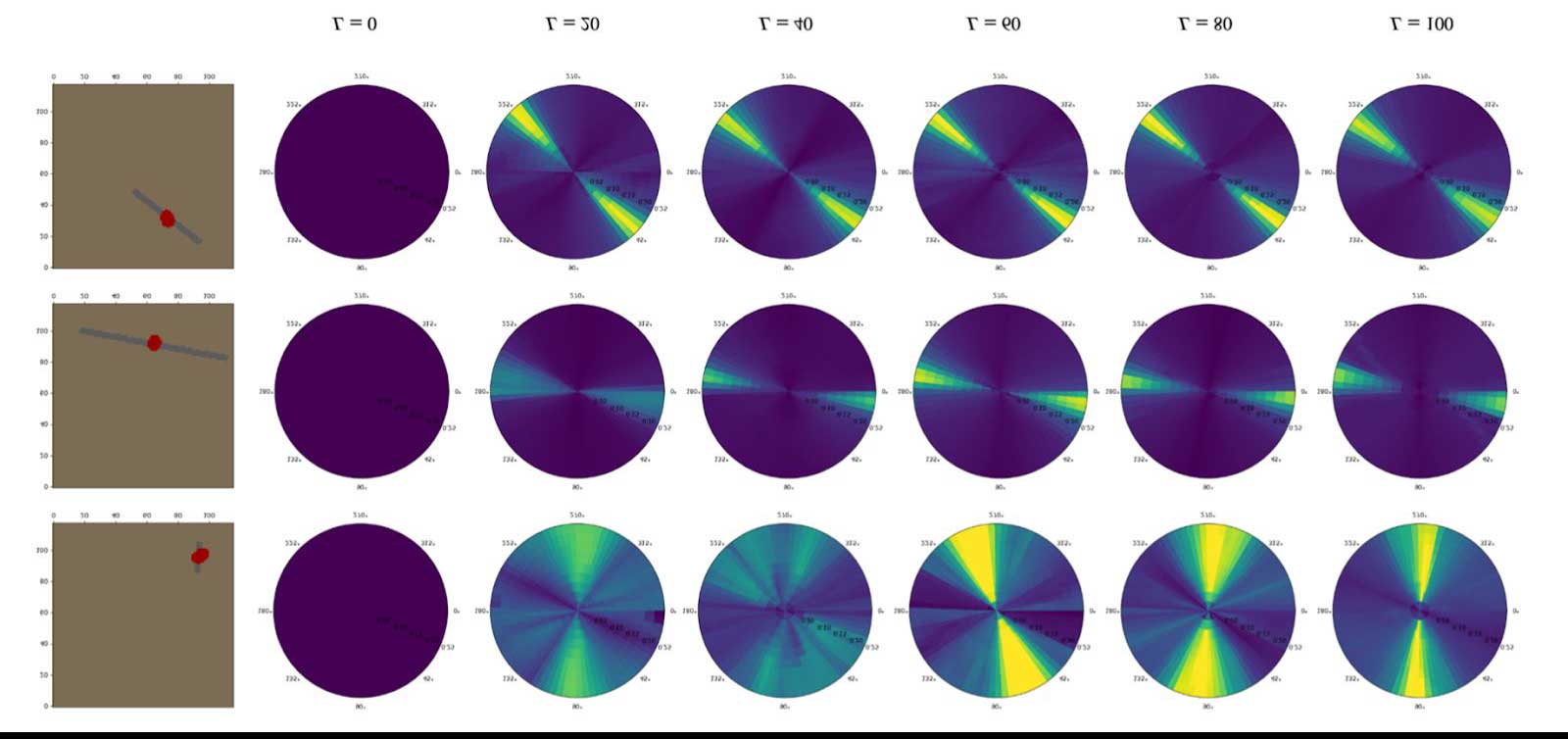
Curious Model Learning
The MIT team is focusing its research on learning models of objects in the environment. They hypothesize that a robot with a curious sub-goal proposal mechanism can learn models that are “better” by using experience from its sub-goals to update the model. In this case, “better” means the model is better suited to succeeding in future tasks.
Publications:
M. Noseworthy, D. Park, R. Paul, S. Roy, N. Roy. Leveraging Past References for Robust Language Grounding. In Conference on Computational Natural Language Learning, 2019.
M. Noseworthy, D. Park, R. Paul, S. Roy, N. Roy. Task-Conditioned Variational Autoencoders for Learning Movement Primitives. In Conference on Robot Learning (CoRL), 2019.
M. Noseworthy, D. Park, R. Paul, S. Roy, N. Roy. Inferring Task Goals and Constraints using Bayesian Nonparametric Inverse Reinforcement Learning. In Conference on Robot Learning (CoRL), 2019.
Compositional Skill Learning
Curiosity-driven exploration means to explore parts of environment about which we do not know. The MIT team hypothesizes that a curious agent should, when faced with a set of training settings that do not have extrinsic goals/rewards, learn useful high-level policies that can be composed in various ways through planning, in order to succeed quickly at longer-horizon tasks (i.e. sample-efficiently, with very little adaptation or data for this new task). The intuition is that at the beginning, the agent will realize there are some environments that are too complex for it, and focus on the ones where it can learn things; later it can go back and (equipped with its new abilities) try again to learn things in more complex environments.
Publications:
A. Ajay, M. Bauza, J. Wu, N. Fazeli, J. Tenenbaum, A. Rodriguez, L. P. Kaelbling. Combining Physical Simulators and Object-Based Networks for Control. In International Conference on Robotics and Automation (ICRA), 2019.
R. Chitnis, L. P. Kaelbling and T. Lozano-Perez. Learning Quickly to Plan Quickly Using Modular Meta-Learning. In International Conference on Robotics and Automation (ICRA), 2019.
R. Chitnis, L. P. Kaelbling and T. Lozano-Perez. Learning What Information to Give in Partially Observed Domains. In Conference on Robot Learning (CoRL), 2018.
Z. Wang, B. Kim and L. P. Kaelbling. Regret bounds for meta Bayesian optimization with an unknown Gaussian process prior. In Neural Information Processing Systems (NeurIPS), 2018.
Z. Wang, C. R. Garrett, L. P. Kaelbling and T. Lozano-Perez. Active model learning and diverse action sampling for task and motion planning. In International Conference on Intelligent Robots and Systems (IROS), 2018.
C. Gehring, L. P. Kaelbling, T. Lozano-Perez. Adaptable replanning with compressed linear action models for learning from demonstrations. In Conference on Robot Learning (CoRL), 2018.
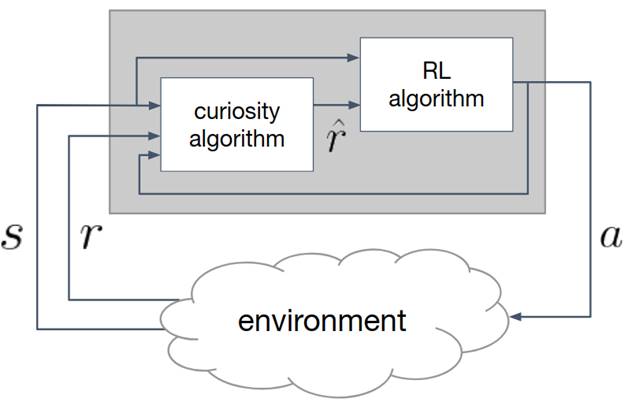
Meta-Learning Curiosity Algorithms
The MIT team aims to find a curiosity module that achieves high total long-term reward in many different environment. They hypothesize that curiosity is an evolutionary-found system that encourages meaningful exploration in order to get high long-term reward, and propose to frame this evolutionary search in algorithm space.
Publication:
F. Alet, M. Schneider, T. Lozano-Perez, L. P. Kaelbling. Meta-learning curiosity algorithms. In International Conference on Learning Representations, 2020.